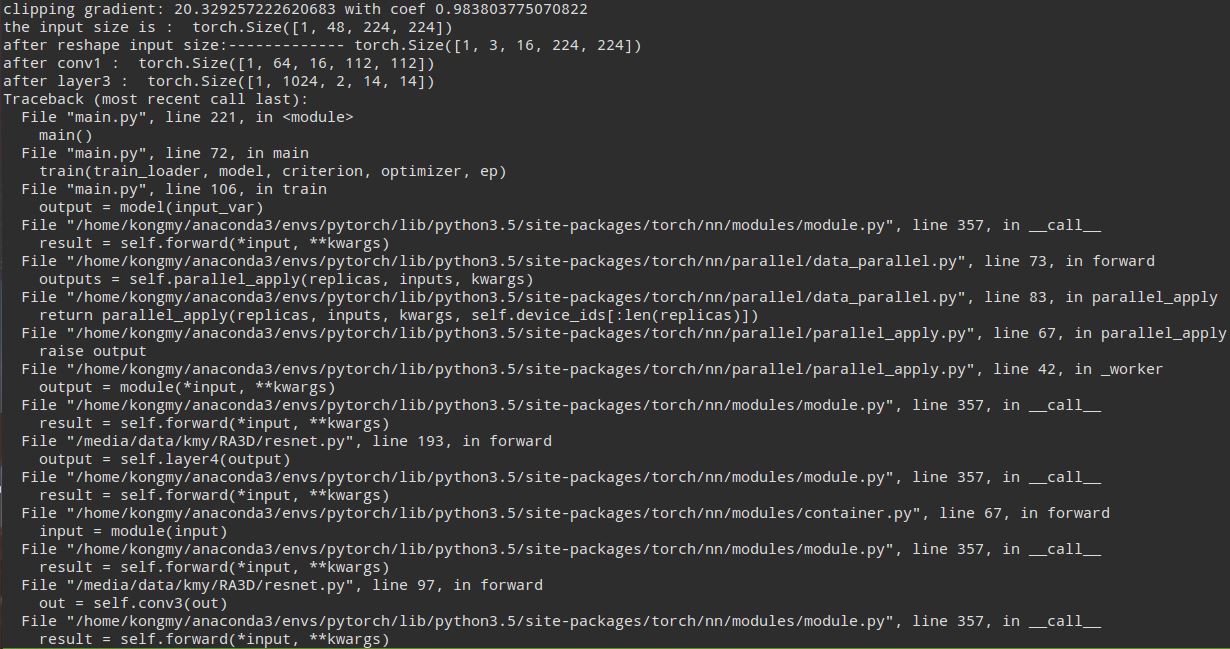
I get batch data from DataLoader. And the length of dataset is not divisible by batch size. All batches work well expect the last one. If I set “drop_last = True” when instantiate DataLoader instance, the error won’t appear.
My dataset length is 11522, batch size is 32. So the length of last batch is 2. And I use two gpus.
I google for an hour, someone said rm -r ~/.nv and restart computer. But my code runs on server , I can’t restart it. Also someone said to set cudnn.benchmark = False. But the same statement on other project works well.
Why encounter the error? It upset me and I dont’ wanna drop the last two data actually. Anyone can help me ?
Which PyTorch version are you using?
Could you add a print statement into your training loop to see, which shape your data has?
I assume you are using DataParallel?
If I recall correctly, there was a bug some time ago, that removed the batch dimension if the size of your batch was divisible by the number of GPUs.
If that’s the case, try to unsqueeze your data using something like this:
# Training loop
for data, target in loader:
if data.dim() == 3:
data.unsqueeze_(0)