I am suffering from a very strange problem and I have to ask someone who might be familiar with it.
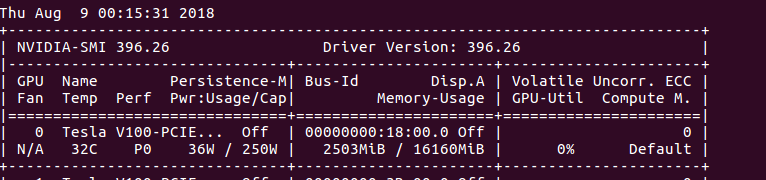
Briefly speaking, 0% gpu-util with a lot of gpu memory (see figure below).
The code I am running is protonets which uses the fancy torchnet frame. I have a Quadro P4000 on my local desktop and a Tesla V100 on the server cluster. The code works well with 50% gpu-util on my local desktop but cannot reach even 1% gpu-util on the cluster with the V100. It turns out the code on the cluster is at least 10 times slower than on the local machine.
After a lot of configurations, both the cluster node and my location desktop have the same settings: python 3.6.5, cuda 9.0, pytorch 0.4.0. The configuration thus is probably not an issue.
I am pretty sure I have applied cuda() to all the possible models, tensors, and you can see that they are indeed loaded into the gpu-memory (2503/16160 MiB, in the picture). But why can’t they go through the computation in gpu?
I initially doubt whether torchnet support V100 or not. But after running a simple example, I found the example ran well on V100.
PS: I didn’t change anything in the source code of the protonets. But it just cannot work on V100, while work well on P4000.
Print output.device to see it output is allocated to cuda:0 or cpu
If it’s allocated in cpu u probably did something wrong.
It may also be a cuda drivers problem or dunno. Not so much info
Yes, I have checked all the inputs and outputs before and after computations. They are all allocated to cuda:0.
Are u working in PC, cluster? u may have wrongly exported environment variables?
I am working on cluster. The key env vars are set to be the same, specified above. But it is just having trouble running on gpu’s on cluster.
cuda: 9.0
pytorch: 0.4.0
python 3.6.5
I think these are the only vars important to the training, right?
Not Really, in professional clusters (ones managed by an administrator) there are usually several versions of cuda and cudnn. It may happen (it happened to me) that when you are exporting environment variables you do it wrongly or pointing to wrong versions. You have to check which version of pytorch you have (it means, which cuda version the pytorch version you installed is compatible with, I guess there are installations for cuda 8 9 9.1 and 9.2 right now) and check what is there available in you cluster.
When you run a job you typically have to export those variables
Those are
CUDA_HOME
LD_LIBRARY
And depending on your cluster some other related to python, pytorch etcetera… it depens a lot on the cluster. Go to the shell and check if those variables exist.
If error is due to hardware compatibility there is no so much you can do. But I guess in the end pytorch layer rely on cuda, and I don’t think cuda drives does not work with those powerful gpus.
Thanks, Juan. I set up the same environments and finally figured out why. I wrote four versions of the code and modify different suspicious parts. I found that function “TransformDataset” from the new pytorch framework torchnet seems incompatible with the gpu V100. As long as I use some conventional dataset class like TensorDataset or run the code on P4000, everything works well. It is quite strange. But since torchnet is new, I think such incompatibility is understandable.