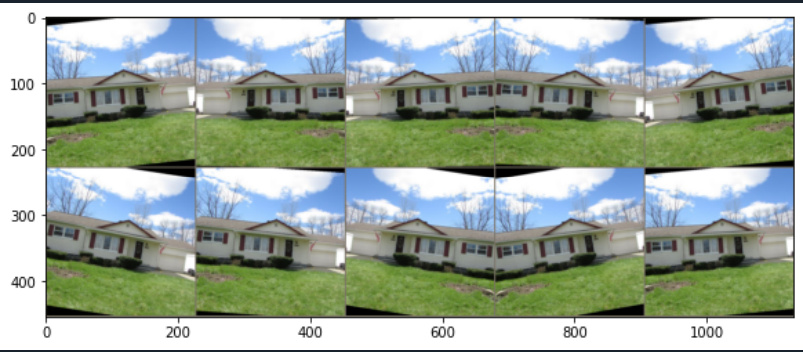
Hi. It seems to me that my data loader is pulling the same image. It’s transforming it differently but it’s still the same image.

I would expect it to pull 10 different images with each batch of 10.
Below is the data loader:
class Inspection_Dataset(Dataset):
"""
df: Dataframe containing all categorical, numerical and image columns
numerical columns: list of numerical columns
cat_columns: list of categorical columns
image: column containing image file name
root_dir: column containing root directory
"""
def __init__(self, df, numerical_columns = None,
cat_columns = None,
image = None,
root_dir = None,
label = None,
transform = None):
#df
self.df = df
#transform
self.transform = transform
#image
self.image_column = image
self.root_dir = root_dir
#length
self.n = df.shape[0]
#output column
self.label = np.array(self.df.loc[:, label])
#cat columns
self.cat_columns = cat_columns if cat_columns else []
self.numerical_columns = [col for col in df[numerical_columns]]
if self.cat_columns:
for column in self.cat_columns:
df[column] = df.loc[:, column].astype('category')
df[column] = df[column].cat.codes
self.cat_columns = np.array(df[cat_columns])
else:
self.cat_columns = np.zeros((self.n, 1))
#numerical columns
if self.numerical_columns:
self.numerical_columns = df[self.numerical_columns].astype(np.float32).values
else:
self.numerical_columns = np.zeros((self.n, 1))
def __len__(self):
return self.n
def __getitem__(self, idx):
idx = list(self.df.index)
image = Image.open(os.path.join(self.df.loc[idx, self.root_dir].values[0],
self.df.loc[idx, self.image_column].values[0]))
image = self.transform(image)
return self.label[idx], self.numerical_columns[idx], self.cat_columns[idx], image
Below is the code I used to test the data loader/print the images.
train_data = Inspection_Dataset(train_sample,
numerical_columns = numerical_columns,
cat_columns = non_loca_cat_columns,
image = 'file',
root_dir = 'root',
label = 'target',
transform = train_transform)
train_loader = DataLoader(train_data, batch_size = 10, shuffle = True)
count = 50
for i in range(count):
for b , (label, numericals, cats, image) in enumerate(train_loader):
break
print('Label:', label.numpy())
im = make_grid(image, nrow=5) # the default nrow is 8
# Inverse normalize the images
inv_normalize = transforms.Normalize(
mean=[-0.485/0.229, -0.456/0.224, -0.406/0.225],
std=[1/0.229, 1/0.224, 1/0.225]
)
im_inv = inv_normalize(im)
# Print the images
plt.figure(figsize=(12,4))
plt.imshow(np.transpose(im_inv.numpy(), (1, 2, 0)));
What am I missing here?