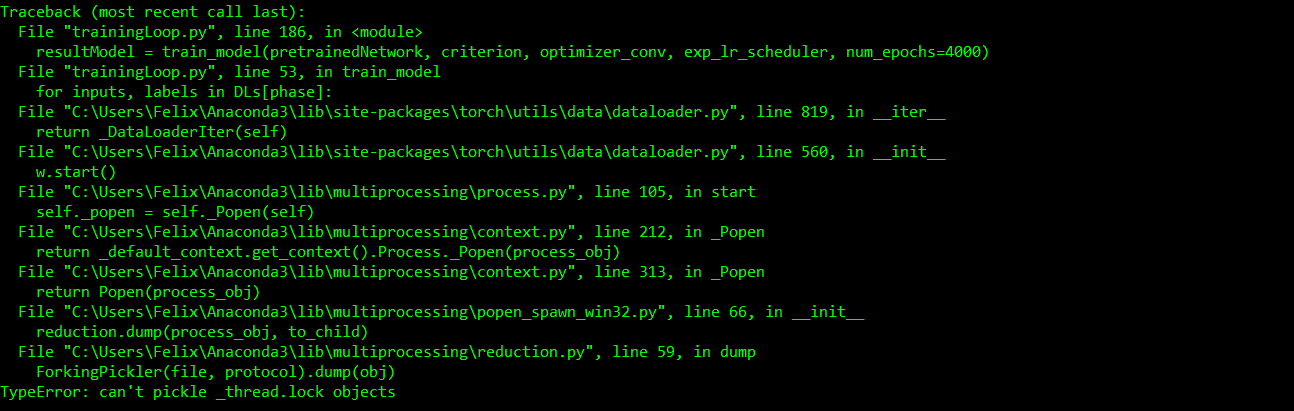
I’m on Windows 10 using Anaconda running Python 3.5.6 and pytorch 1.0.0 (py3.5_cuda100_cudnn7_1 [cuda100] pytorch). I’m trying to use a custom dataset with the Dataloader class and keep getting a crash due to a threading error.
The error occurs when the code iterates over the dataloader using the custom dataset. The dataset loads a document from mongodb and the underlying class extracts the images stored in the db, other data and label.
class mongoDatasetLoader(torch.utils.data.Dataset):
def __init__(self,transform):
self._label_dtype = np.int32
self.imageTransform = transform
self.mongoDB = mongoAPI()
self.ids = [elem['_id'] for elem in list(self.mongoDB.tdb.find({}, {'_id': 1}))]
self.loadData = self.ids
random.seed()
def __len__(self):
return len(self.loadData)
def __getitem__(self, i):
profile = self.mongoDB.restore_profile(self.loadData[i])
img = profile.images[0]
img = self.imageTransform(img)
# How to make the bool conversion less horrible??
return img, torch.from_numpy(np.array([int(profile.liked)])).type(torch.long)
Is the dataset missing some definitions required by the dataloader or is this issue a little hairier?
1 Like
Is your code running fine using num_workers=0?
If so, could you add the if-clause protection as described in the Windows FAQ?
Yes, the code is fine when there are no threads.
I just tested it with the if-clause and still get the same error.
Hi, did you finally solve this problem, I encountered the same problem when num_workers> 0.
I found a feasible solution. Because pymongodb is not fork-safe, we must be careful about fork() when using MongoClient instances. In particular, MongoClient instances must never be copied from the parent process to the child process. Instead, the parent process and each child process must create their own MongoClient instance.
here is my code. This does work, when num_workers > 0.
import torch
from torch.utils.data import Dataset, DataLoader
import pymongo
from pymongo import MongoClient
client = MongoClient('localhost', 27017, connect=False)
db = client.dataset
collection = db.train
class MyDataset(Dataset):
def __init__(self, trian=True):
self.trian = trian
def __getitem__(self, idx):
if self.train:
data_i = collection.find_one({'index': idx})
else:
data_i = collection.find_one({'index': idx})
return data_i
def __len__(self):
return collection.estimated_document_count()
def collate_fn(recs):
forward = list(map(lambda x: x['forward'], recs))
backward = list(map(lambda x: x['backward'], recs))
def to_tensor_dict(recs):
values = torch.FloatTensor(list(map(lambda r: r['values'], recs)))
masks = torch.FloatTensor(list(map(lambda r: r['masks'], recs)))
deltas = torch.FloatTensor(list(map(lambda r: r['deltas'], recs)))
evals = torch.FloatTensor(list(map(lambda r: r['evals'], recs)))
eval_masks = torch.FloatTensor(list(map(lambda r: r['eval_masks'], recs)))
forwards = torch.FloatTensor(list(map(lambda r: r['forwards'], recs)))
return {'values': values, 'forwards': forwards, 'masks': masks, 'deltas': deltas,
'evals': evals, 'eval_masks': eval_masks}
# transform recs to tensor dict
ret_dict = {'forward': to_tensor_dict(forward), 'backward': to_tensor_dict(backward)}
ret_dict['labels'] = torch.FloatTensor(list(map(lambda x: x['label'], recs)))
ret_dict['is_train'] = torch.FloatTensor(list(map(lambda x: x['is_train'], recs)))
return ret_dict
def get_loader(batch_size = 64, shuffle = True):
data_set = MyDataset()
data_iter = DataLoader(dataset = data_set,
batch_size = batch_size,
num_workers = 4,
shuffle = shuffle,
pin_memory = True,
collate_fn = collate_fn )
return data_iter
if __name__ == '__main__':
data_loader = get_loader(batch_size=32, shuffle = True)
for idx, data in enumerate(data_loader):
print(idx)
1 Like
I haven’t played with this code in a while. Your suggestion looks good, I’ll give it a shot and get back to you with the results (probably this weekend).