Hello All,
I’m experiencing a strange behavior while dataloader loading my data (calling get_item) if I use different lengths of data. My actual dataset is around 200K and self.data is holding list/np.array of dictionary items which each item has fixed number of key-val(data_file_name, data_file_path and etc.) pairs. In get_item: I simply do
sample = self.data[index]
np.load(sample.get('data_file_path'))
When I set my dataloader’s batch_size = 30 and num_workers = 4 and use full dataset, I get very slow dataloading process. (Left Image)
However, when I keep everything same (same CustomDataset, same DataLoader, batch_size = 30, num_workers = 4 and etc.) but use only subset of my dataset which is around 5k then dataloading process is very fast.(Right Image)
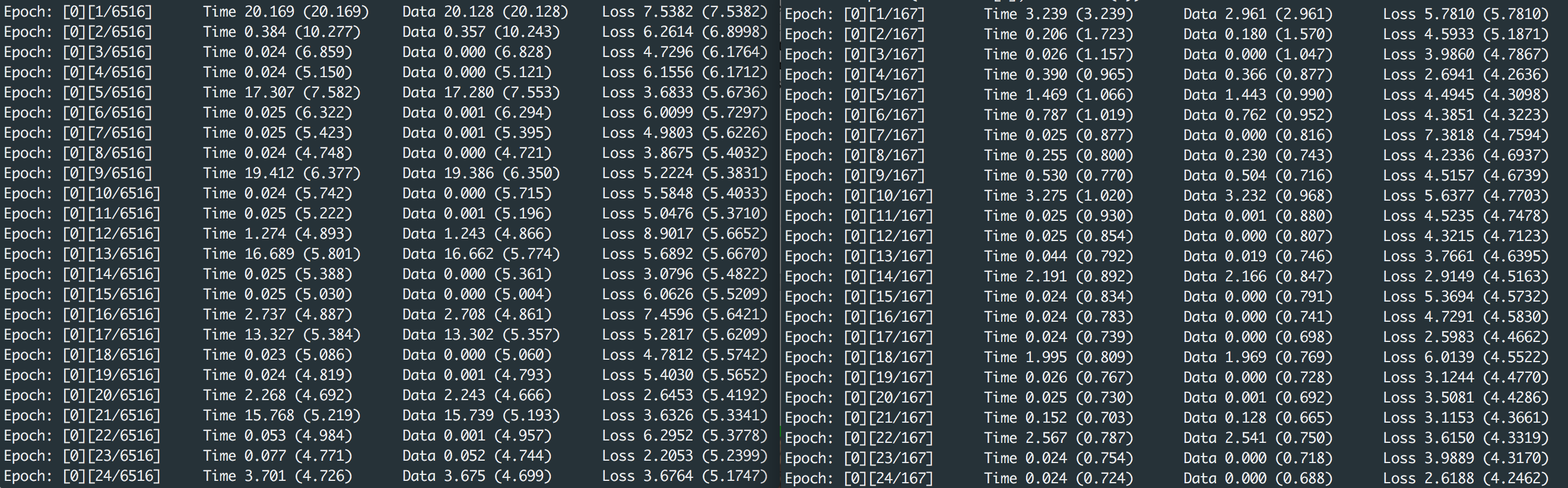
What would be the possible explanation for this? and Is there any workaround to solve this?