My pytorch model can run on a single gpu correctly. But when I use DataParallel to run it on multiple gpus ,I got an error : arguments are located on different GPUs
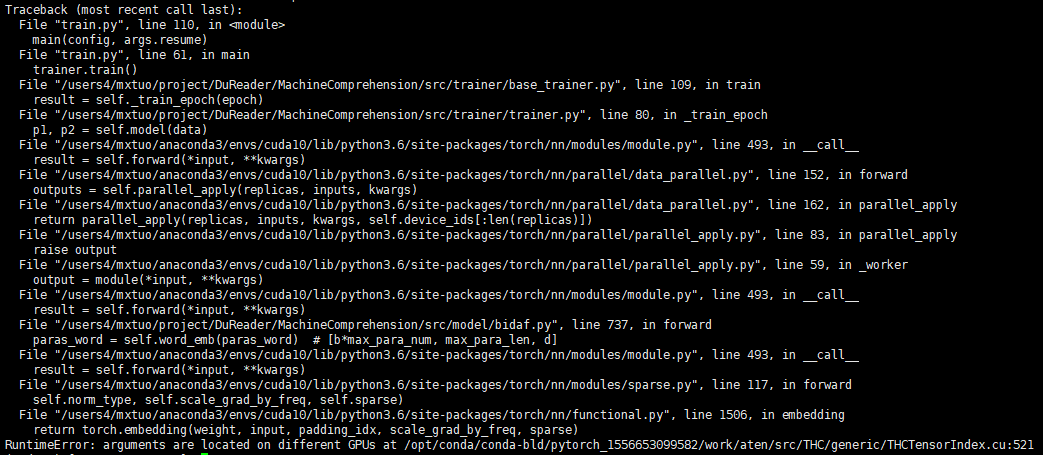
It seems that embedding parameters and input tensor are on different gpu. So I print the divice of them:
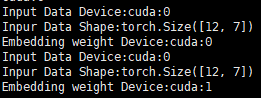
The batch size is 12 and gpu num is 2. As is shown above, it has two problem:
- The batch size should be 6 instead of 12 (cause it should be split into two pices by DataParallel).
- The embedding weigh are parallel to two gpus(cuda:0 and cuda:1) but the input data on the same gpu.
I use torchtext to load data and the input data is on the cuda:0.
I use the following code to parallelize model:
self.device, device_ids = self._prepare_device(config['n_gpu'])
self.model = model.to(self.device)
# data parrallel
if len(device_ids) > 1:
self.model = torch.nn.DataParallel(model, device_ids=device_ids)
...
def _prepare_device(self, n_gpu_use):
"""
setup GPU device if available, move model into configured device
"""
n_gpu = torch.cuda.device_count()
if n_gpu_use > 0 and n_gpu == 0:
self.logger.warning(
"Warning: There\'s no GPU available on this machine, training will be performed on CPU.")
n_gpu_use = 0
if n_gpu_use > n_gpu:
msg = "Warning: The number of GPU\'s configured to use is {}, but only {} are available on this machine.".format(
n_gpu_use, n_gpu)
self.logger.warning(msg)
n_gpu_use = n_gpu
device = torch.device('cuda:0' if n_gpu_use > 0 else 'cpu')
list_ids = list(range(n_gpu_use))
return device, list_ids
And I use the completely same logic to parallelize another model and it works!