Hi everyone, I have a problem with my DataParallel model. I am wrapping my model with DataParallel, as I am trying to take advantage of 2 GPUs I have. However, when I check the GPUs performance when training the model, I notice that my model is using exclusively only one GPUs. I am not sure why is this happening, and I was wondering whether someone knows how to fix this issue.
class SummModel(nn.Module):
def __init__(self, hidden_size=768):
super(SummModel, self).__init__()
self.hidden_size = hidden_size
self.encoder = BertModel.from_pretrained('bert-base-uncased')
"""
Method that represents one forward step in the model.
Parameters:
- text_id : list of tokenized texts
- summary_id : list of tokenized summaries
- candidate_id : list of list of N candidates
"""
def forward(self, text_id, candidate_id, summary_id):
batch_size = len(text_id) # number of tokenized texts
pad_id = 0 # pad symbol for Bert
# document embedding
mask = ~(text_id == pad_id)
last_hidden_state = self.encoder(text_id, attention_mask=mask)[0] # taking the state of the last layer in Bert model
doc_emb = last_hidden_state[:, 0, :]
assert doc_emb.size() == (batch_size, self.hidden_size)
# summary embedding
mask = ~(summary_id == pad_id)
last_hidden_state = self.encoder(summary_id, attention_mask=mask)[0]
sum_emb = last_hidden_state[:, 0, :]
assert sum_emb.size() == (batch_size, self.hidden_size)
# golden summary score
summary_score = torch.cosine_similarity(sum_emb, doc_emb, dim=-1)
# candidate embedding
candidate_num = candidate_id.size(1)
candidate_id = candidate_id.view(-1, candidate_id.size(-1)) # reshaping the tensor
mask = ~(candidate_id == pad_id)
last_hidden_state = self.encoder(candidate_id, attention_mask=mask)[0]
candidate_emb = last_hidden_state[:, 0, :].view(batch_size, candidate_num, self.hidden_size)
assert candidate_emb.size() == (batch_size, candidate_num, self.hidden_size)
# calculate candidate scores
doc_emb = doc_emb.unsqueeze(1).expand_as(candidate_emb)
candidate_scores = torch.cosine_similarity(candidate_emb, doc_emb, dim=-1)
assert candidate_scores.size() == (batch_size, candidate_num)
return {"candidate_scores": candidate_scores, "summary_score": summary_score}
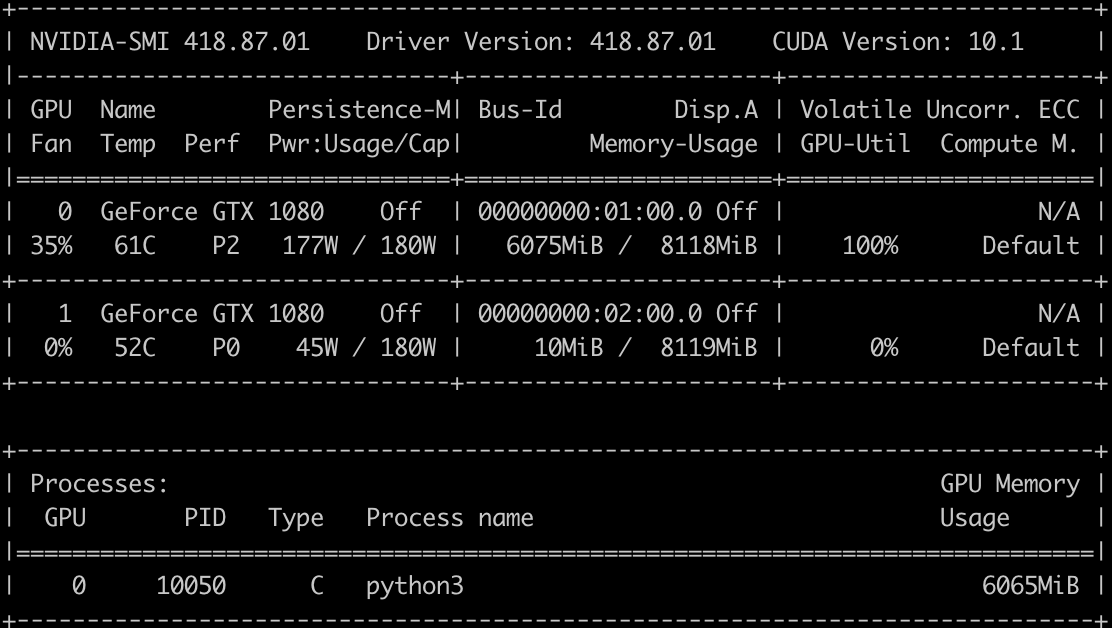
EDIT: Fixed it by increasing batch size from 1 to 2. ![]()