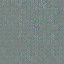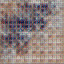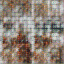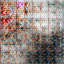I have a DCGAN (code available here: https://github.com/Grubzerusernameisavailable/DCGAN-pytorch/blob/master/pytorch_gan.ipynb), but it has a big problem: it doesnt work. In the beginning if the generator is fed some random noise, outputs are also a uniform noise as expected, but at least they change with whatever we input in. But almost immidiately after training starts it falls into something that looks like a mode collapse, but worse: images not only stay almost completly identical no matter the input (they may have some variance, but it is imperceptible for me), but they also have no traits of original dataset (256 * 256 rgb living room images):
Here is how typical output looks (from one of the experiments i ran with reduced (64*64 RGB) resolution):
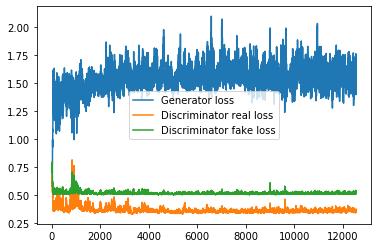
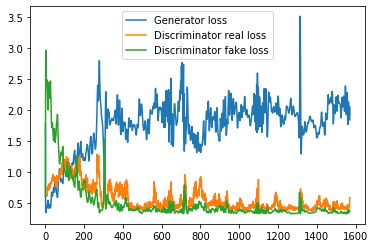
And loss from one of the runs, sampled each batch (graph looks kinda the same, no matter what i do):
Things that i tried to fix it:
Deeper/shallower generator. Change structure of generator to 16->3 or 128->3 Conv2d channels at output, no effect
Change first linear layer output depth and resolution: all kinds of combinations between 2x2, 4x4, and 8x8 resolutions and 256,512, 1024 and 2048 depth
Varying input noise space, 50,100,300
Feeding noise directly through .view omitting linear layer as input (noise size 65536 → 1024,8,8)
Vary discriminator depth, dropout values and channels at Conv2d layers
Playing around with loss functions in a despair
None of it worked. One behavior that i noticed is a “blobby” nature of some outputs, where output would typically have a blob of one color with a background of another color, and a high-res grid pattern overlayed on top of that, colors of which change in the “blob” and backgground
I am kinda new to ML community, and might be missing some key element, but this amount of absence of any change in behavior no matter what i do, is starting to drive me kinda crazy, help me please
Even though i wrote my dcgan from another tutorial, yeah, i read this one too, verified that my training loop is ok, found a method for random weight initialization, and remembered that i should BachNorm2d my layers. Still didnt help though
I noticed when you plot the image you don’t do gen.eval(). This is important because of the BatchNorm. Also why using dropout with so low p? Have you tried with p=0.5 , or using BatchNorm in both generator and discriminator?
I thought that bad generator performance was due to weak discriminator, so i tried making it ‘stronger’ by reducing how much it forgets during training
Completly forgot about .eval, ill try that tomorrow, and Discriminator BatchNorm too, will post results here
Alright, i’ve done some tests, and results are as following:
on the same architecture as before, no changes using .eval before image sampling, though i kept using it since that is how i should’ve done it from the beginning
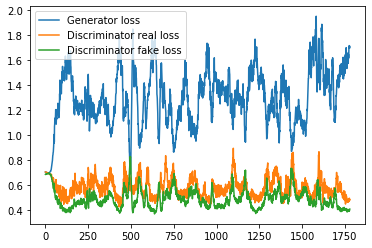
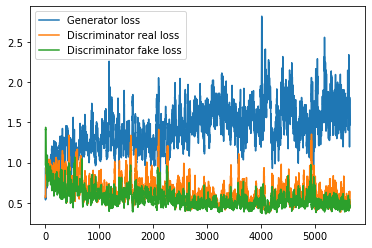
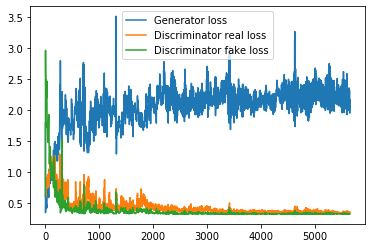
Also i’ve done three more tests: discriminator dropout 0.4, discriminator batchnorm, and both at the same time, here is how they look, results from:
Dropout 0.4 with no batchnorm 10 epochs:
Batchnorm with 0.4 dropout 36 epochs:
Batchnorm only 36 epochs:
I feel like batchnorm with no dropout works the best, even at 10th epoch:
But the problem of mode collapse still remains unsolved. No matter the input, generator creates the same pictures (up to pixel-by-pixel similarity). Any remedeis for that? I’ve heard that Unrolled GANs solve this problem, but maybe there is something else? Also, i can see the problem of big repetitive patterns. Is this something similar to checkerboard artifacts that transpose layers produce, just carried over from earlier layers?
So, after some more testing, i came to a conclusion:
My model (and model from dcgan pytorch tutorial i switched to) did not have enough capacity for dataset i was using. After switching to CelebA dataset, model worked as is it was suppose to. My theory is that because of high variety of images in living room dataset, different environments, camera angles, etc. and low model capacity for this task, it was forced into creating blurry approximations of them, hardly capturing even a color scheme, and falling into mode collapse, since size of latent vector and model capacity were not big enough to capture all parameters that it needed.
Start with simple datasets, for example, CelebA, and test on them. If the problem is in the model’s architecture, it would show it here
If model experiences mode collapse, increase its capacity, and size of latent vectors
In my case i’ve noticed a phenomenon of “bouncing” in the beginning of training process: images start as noise, then become more realistic (Sort of. There are some color patches, in case of CelebA dataset there is a blurry kinda-face figure in the center), but after that they come back to noise, then back to sort-of realistic images, and then going back and forth a few times, before settling at final result that improves over time. Not sure if it is normal, but in my case it went through that stage, and then worked as expected, hopefully someone can explain to me whether it is normal or not
Thanks to everyone who helped me, problem is solved