And indeed, even interpolating in the latent space seems to produce a large variety of digits (to produce the plot below, I generated 3 random noises and then interpolated the noise to feed in the generator) (see the github page. I cannot put more than 1 image or more than 2 links)
But, when it turns to plot the losses, these seems to me unexpected.
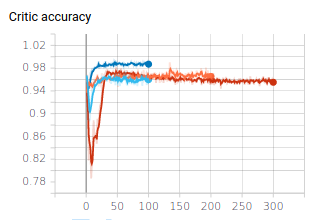
They are all consistent : a high generator loss (that I want to be minimized actually…), almost 90% accuracy for the discriminator. This indicates the discriminator is able to distinguish the fakes from the reals 90 % of the time but when I see the digits the generator generates, I see no obvious things and it seems to generate a variety of shapes which seems to indicate this is not a mode collapse.
I would say that all the samples seem reasonably ok. And they all show similar behaviors in the metrics which I still find very surprising.
For example, if I plot the accuracy of the discriminator (I would have expected it to be at 50% when the fakes look real):
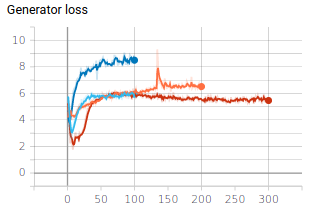
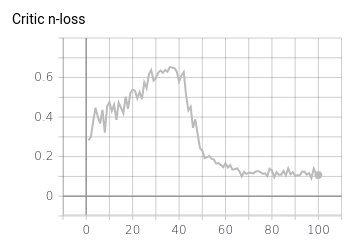
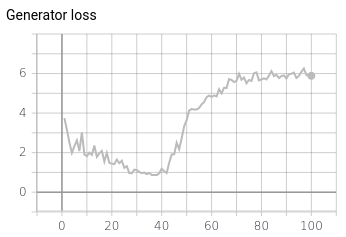
And if I plot the loss of the generator (I would have expected it to be low when the generated samples look real):
And finally, because I really find it funny (even impressive actually), if I take the model trained on FashionMNIST and SVHN and let me generate samples by interpolating in the latent space using 3 seeds (for the top-left, top-right and bottom-right).
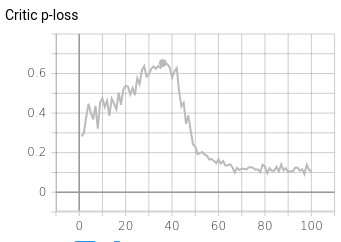
A follow-up. I was suggested that the discriminator might be overfitting. Indeed, it seems to be the case.
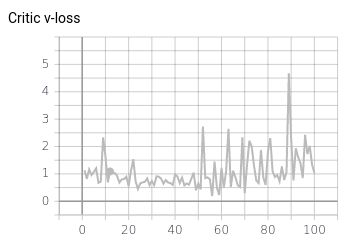
I evaluated separately the cross entropy loss of the discriminator on the positive samples (coming the train split of the dataset), on the negative samples (generated by the generator) and on a validation positive samples (coming from the validation split of the dataset) :
I interpret this as the discriminator being overspecialized on the training set positive samples considering everything else as a negative (like a one class classifier) and therefore I suppose this is a failure since the discriminator would train the generator to generate only the samples that are exactly (or almost) similar to the samples from the training set.
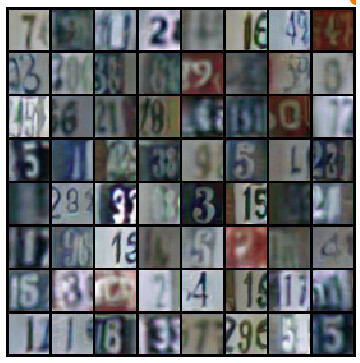
To be honest, I have the feeling this is not exactly what is happening as interpolating in the latent space produces quite diverse images and, by the way, the generator loss is pretty high. For completeness, the generator loss and some generated samples are displayed below; Even though the generator loss is high , I feel like the samples are again not that bad.
For complete completeness, this is generated with GitHub - jeremyfix/gan_experiments , tag v2, and running python3 main.py train --dataset SVHN --dropout 0.0 --wdecay 0.0
In the next post, soon, I will post some results when regularizing the discriminator.
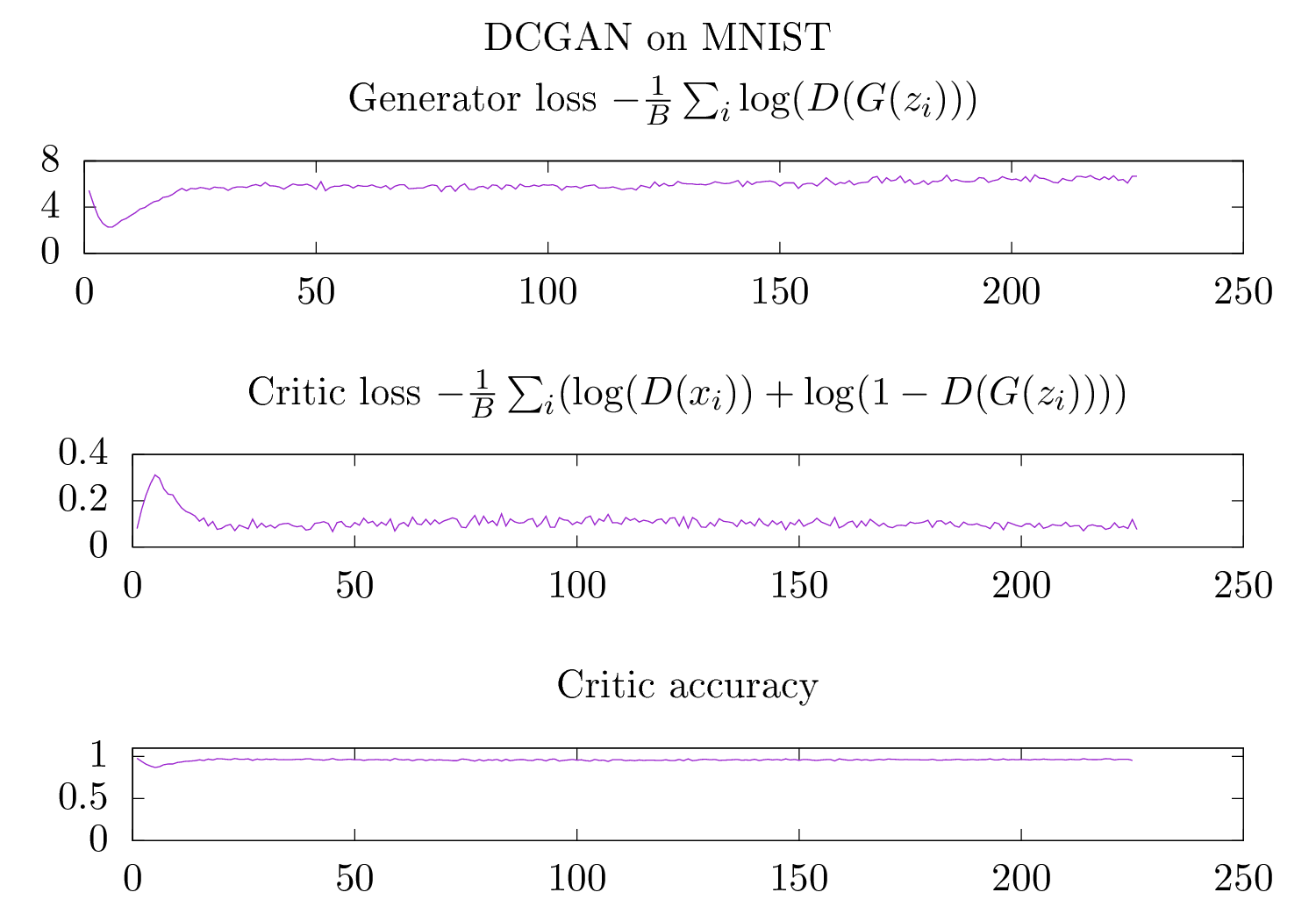



{kind=link}