Hi,
I am trying to implement the main idea in Massively Parallel Video Networks. In the paper, the authors implement model parallelism for training video networks by giving the outputs of each layer to the next layer as usual but to the next time step. This way, they can process layers independently on different GPUs. The following figure shows the most basic case:
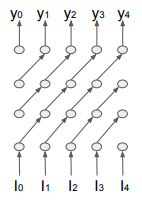
This photo shows the network unrolled over time. At every time instant, for this case, we have 4 different layers and each of these 4 layers can be processed independently on separate GPUs.
To do this I want to use hopefully, something simple. However, I am having trouble understanding if I can use DDP for this. Essentially, I want to divide my model into independent blocks and pass the gradient in the direction of the arrows. Can I use DDP with model parallel as given here. If so, how to do this for a big model where I can choose how I define my sub-blocks.
As a further question: In the paper, they also implement the same idea on a CPU. Is there some function in PyTorch which can achieve this task.
Note: We cannot use nn.DataParallel() because the training setting is an online training and we want to process frames one by one as they come.
Thanks in advance.