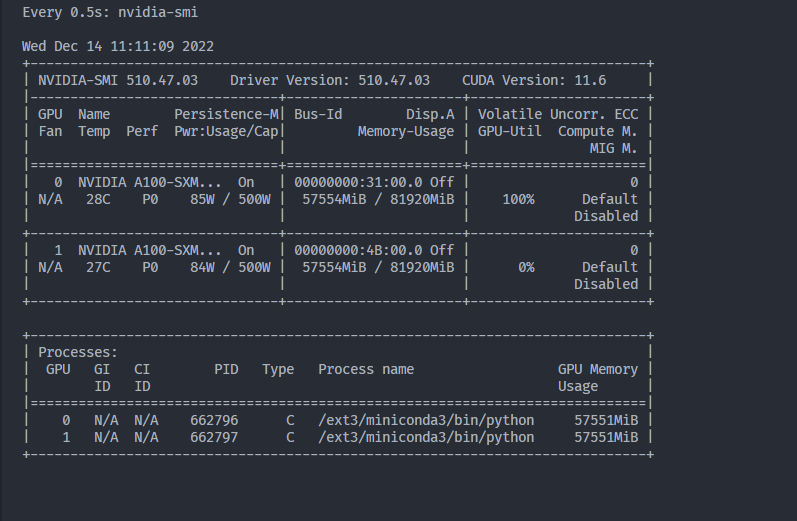
Hi, I am resently training a baseline of MAE on two A100 80G, however, the nvida-smi shows that the utilization of one GPU is zero for a long time, then both GPU reaches full utilization for a very short of time (forward pass I guess?) I am not sure what is cause. Below is my full trainer class code.
import os
from functools import partial
from pathlib import Path
from typing import Tuple
from matplotlib import pyplot as plt
import torch
import torch.distributed as dist
import torch.nn.functional as F
import torchvision.transforms as T
import torchvision.transforms.functional as TF
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.optim import AdamW, Optimizer
from torch.optim.lr_scheduler import LambdaLR, _LRScheduler
from torch.utils.data import DataLoader, DistributedSampler
from torch.distributed.optim import ZeroRedundancyOptimizer
from torch.utils.tensorboard import SummaryWriter
import math
from matplotlib import rcParams
from . import datasets
from . import nn
from .utils import lr_lambda
from datetime import datetime
import numpy as np
import random
RANDOM_SEED = 19971222
torch.manual_seed(RANDOM_SEED)
np.random.seed(RANDOM_SEED)
random.seed(RANDOM_SEED)
class Trainer:
def __init__(self, config: dict, **kwargs) -> None:
self.config = config
self._dataset = None
self._model = None
self._optimizer = None
self._scheduler = None
self._logdir = None
self._dataset = None
self._logger = None
self.curr_epoch = None
self._sampler = None
self._steps_per_epoch = None
self.local_rank = 0
self.world_size = 1
self.global_steps = 0
self.batch_steps = 0
self.total_batch_steps = 0
self._dataloader = None
self._device = None
self.start_time = datetime.now()
if dist.is_available() and dist.is_initialized():
self.local_rank = dist.get_rank()
self.world_size = dist.get_world_size()
@property
def device(self):
if self._device is None:
self._device = torch.device('cuda', self.local_rank) if torch.cuda.is_available() else torch.device('cpu')
return self._device
@property
def model(self):
if self._model is None:
self._model = nn.MAE(**self.config)
self._model.to(self.device)
if dist.is_available() and dist.is_initialized():
self._model = DDP(self._model, device_ids=[self.local_rank])
return self._model
@property
def logdir(self):
if self._logdir is None and self.local_rank == 0:
logdir = self.config["logdir"]
Path(logdir).mkdir(parents=True, exist_ok=True)
existing_versions = [
version.split("_")[1]
for version in os.listdir(logdir)
if version.startswith("version_")
]
my_version = (
0
if len(existing_versions) == 0
else max([int(version) for version in existing_versions]) + 1
)
self._logdir = os.path.join(logdir, "version_" + str(my_version))
Path(self._logdir).mkdir(parents=True, exist_ok=True)
return self._logdir
@property
def steps_per_batch(self):
if self._steps_per_epoch is None:
self._steps_per_epoch = len(self.dataloader)
return self._steps_per_epoch
@property
def total_steps(self):
return self.steps_per_batch * self.config['max_epochs']
@property
def logger(self):
if self._logger is None and self.local_rank == 0:
self._logger = SummaryWriter(self.logdir)
return self._logger
def init_optims(self) -> Tuple[Optimizer, _LRScheduler]:
if dist.is_available() and dist.is_initialized() and self.config['zero']:
optimizer = ZeroRedundancyOptimizer(self.model.parameters(), AdamW, lr=self.config['lr'], betas=self.config['betas'], weight_decay=self.config['weight_decay'])
else:
optimizer = AdamW(self.model.parameters(), lr=self.config['lr'], betas=self.config['betas'], weight_decay=self.config['weight_decay'])
scheduler = LambdaLR(optimizer, partial(lr_lambda.cosine_warmup_lr_lambda, 0, self.config['warmup_epochs'] * self.steps_per_batch, self.total_steps))
return optimizer, scheduler
def __call__(self, x: torch.Tensor) -> torch.Tensor:
self.model.eval()
with torch.no_grad():
return self.model(x)
@property
def sampler(self):
if self._sampler is None and dist.is_available() and dist.is_initialized():
self._sampler = DistributedSampler(self.dataset, shuffle=True, seed=RANDOM_SEED)
return self._sampler
@property
def dataloader(self):
if self._dataloader is None:
self._dataloader = DataLoader(
self.dataset,
batch_size=self.config['batch_size'],
shuffle=(self.sampler is None),
sampler=self.sampler,
num_workers=self.config['num_workers'],
drop_last=True
)
return self._dataloader
@property
def transform(self):
return T.Compose([
T.Resize(self.config['image_size']),
T.CenterCrop(self.config['image_size']),
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
])
@property
def target_transform(self):
return T.Compose([
T.Resize(self.config['image_size']),
T.CenterCrop(self.config['image_size']),
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
])
def inverse_normalize(self, x: torch.Tensor):
x = TF.normalize(x, [-0.485/0.229, -0.456/0.224, -0.406/0.225], [1/0.229, 1/0.224, 1/0.225])
x = x.clamp(0, 1)
return x
@property
def dataset(self):
if self._dataset is None:
self._dataset = datasets.ImageFolder(self.config['dataset_dir'], transform=self.transform, target_transform=self.target_transform)
return self._dataset
def checkpoint(self):
if self.local_rank == 0:
ckpt_dir = Path(self.logdir) / "checkpoints"
ckpt_dir.mkdir(parents=True, exist_ok=True)
ckpt_path = ckpt_dir / f"epoch_{self.curr_epoch}.pth"
if dist.is_available() and dist.is_initialized():
torch.save(self.model.module.state_dict(), ckpt_path)
else:
torch.save(self.model.state_dict(), ckpt_path)
def mask_image(self, x: torch.Tensor, patch_perm: torch.Tensor, fill_value: float = 0) -> torch.Tensor:
x = F.unfold(x, self.config['patch_size'], stride=self.config['patch_size'])
masked = torch.arange(x.size(-1), device=patch_perm.device)
masked = torch.isin(masked, patch_perm, invert=True)
x[..., masked] = fill_value
x = F.fold(x, self.config['image_size'], self.config['patch_size'], stride=self.config['patch_size'])
return x
def visualize(self, y: torch.Tensor, yh: torch.Tensor, patch_perm: torch.Tensor, hint_perm: torch.Tensor, noise_perm: torch.Tensor, **kwargs) -> torch.Tensor:
y = self.inverse_normalize(y).detach()
yh = self.inverse_normalize(yh).detach()
fig, ax = plt.subplots(2, 4, figsize=(20, 10))
for i in ax:
for j in i:
j.set_xticks([])
j.set_yticks([])
rcParams['font.family'] = 'serif'
rcParams['font.weight'] = 'bold'
rcParams['font.style'] = 'italic'
rcParams['font.size'] = 20
rcParams['axes.labelsize'] = 20
ax[0, 0].imshow(y.permute(1, 2, 0).cpu().numpy())
ax[0, 1].imshow(self.mask_image(y, patch_perm).permute(1, 2, 0).cpu().numpy())
ax[0, 2].imshow(self.mask_image(y, hint_perm).permute(1, 2, 0).cpu().numpy())
ax[0, 3].imshow(self.mask_image(y, noise_perm).permute(1, 2, 0).cpu().numpy())
ax[1, 0].imshow(yh.permute(1, 2, 0).cpu().numpy())
ax[1, 1].imshow(self.mask_image(yh, patch_perm).permute(1, 2, 0).cpu().numpy())
ax[1, 2].imshow(self.mask_image(yh, hint_perm).permute(1, 2, 0).cpu().numpy())
ax[1, 3].imshow(self.mask_image(yh, noise_perm).permute(1, 2, 0).cpu().numpy())
ax[0, 0].set_ylabel('Original Image')
ax[1, 0].set_ylabel('Reconstructed Image')
ax[0, 0].set_title('Full')
ax[0, 1].set_title('Patches')
ax[0, 2].set_title('Hints')
ax[0, 3].set_title('Noise')
fig.tight_layout()
return fig, ax
def log(self, loss: torch.Tensor, X: torch.Tensor, y: torch.Tensor, yh: torch.Tensor, patch_perm: torch.Tensor, hint_perm: torch.Tensor, noise_perm: torch.Tensor, curr_lr: float, **kwargs):
self.logger.add_scalar('Train/Loss', loss.item(), self.global_steps)
fig, ax = self.visualize(y, yh, patch_perm, hint_perm, noise_perm)
self.logger.add_figure('Train/Reconstruction', fig, self.global_steps)
plt.close(fig)
elapsed_time = 'N/A'
finish_time = 'N/A'
if self.global_steps > 0:
curr_time = datetime.now()
elapsed_time = curr_time - self.start_time
time_per_step = elapsed_time / self.global_steps
total_time = time_per_step * self.total_steps
finish_time = self.start_time + total_time
elapsed_time = str(elapsed_time).split('.')[0]
finish_time = str(finish_time).split('.')[0]
batch_progress = self.batch_steps / self.total_batch_steps
print(f'Epoch: {self.curr_epoch:4d}/{self.config["max_epochs"]}, Batch: {batch_progress:.2%}, Loss: {loss.item():.4f}, LR: {curr_lr:.2e}, Time: {elapsed_time}, ETA: {finish_time}', flush=True)
def train(self):
optimizer, scheduler = self.init_optims()
for ep in range(self.config['max_epochs']):
self.curr_epoch = ep
if self.sampler is not None:
self.sampler.set_epoch(ep)
self.total_batch_steps = len(self.dataloader)
self.model.train()
for batch_idx, (X, y) in enumerate(self.dataloader):
self.batch_steps = batch_idx
X = X.to(self.device)
y = y.to(self.device)
yh, patch_perm, hint_perm, noise_perm = self.model(X)
loss = F.mse_loss(yh, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
scheduler.step()
curr_lr = scheduler.get_last_lr()[0]
if self.local_rank == 0 and self.global_steps % self.config['refresh_rate'] == 0:
self.checkpoint()
self.log(loss, X[0], y[0], yh[0], patch_perm, hint_perm, noise_perm, curr_lr)
self.global_steps += 1
compare to the the “zero utilization” time, the “full utilization” is negligible, and my training gonna ends in 2024…