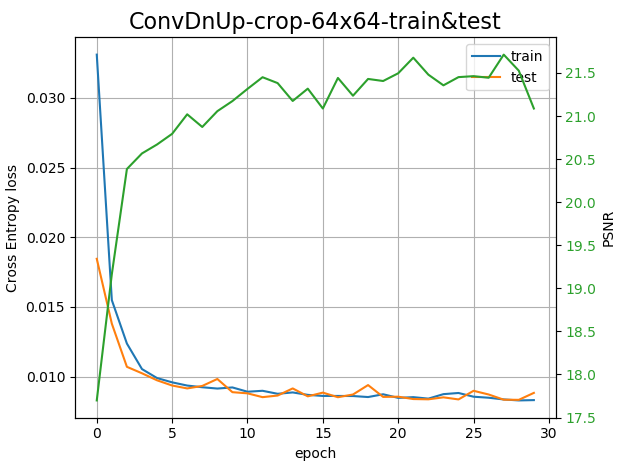
I face a problem that puzzling me. I intend to use several denoiser architectures to evaluate their performances for my use-case. In the following I show the train/test losses as well as the Peak Signal to Noise Ratio (PSNR) which a kind of accuracy metric between an input image (original) and the denoised version if one adds a noise to the original. So, schematically
I_orig -> "add noise" -> I_noisy=I_orig + Noise -> "denoise" -> I_denoised
and then compute the MSEloss(I_orig, I_denoised) and the PSNR.
So, far so good. Now, let me give some details. Concerning the training phase
def train(args, model, device, train_loader, transforms, optimizer, epoch, use_clipping=True)
model.train()
transf_size = len(transforms)
train_loss = 0 # to get the mean loss over the dataset
for i_batch, img_batch in enumerate(train_loader):
batch_size = len(img_batch)
new_img_batch = torch.zeros(batch_size,1,args.crop_size,args.crop_size)
for i in range(batch_size):
# perform data augmentation to get new_img_batch
(... same code ...)
# add gaussian noise
new_img_batch_noisy = new_img_batch \
+ args.sigma_noise*torch.randn(*new_img_batch.shape)
if use_clipping:
scaler = MinMaxScaler()
for i in range(batch_size):
new_img_batch[i] = scaler(new_img_batch[i])
new_img_batch_noisy[i] = scaler(new_img_batch_noisy[i])
# send the inputs and target to the device
new_img_batch, new_img_batch_noisy = new_img_batch.to(device), \
new_img_batch_noisy.to(device)
# perform the optimizer loop
optimizer.zero_grad()
outputs = model(new_img_batch_noisy)
loss = F.mse_loss(outputs, new_img_batch)
train_loss += loss.item()
loss.backward()
optimizer.step()
return train_loss/len(train_loader)
For the test this is essentially the same code but
- I switch to
model.eval() - I use
with torch.no_grad():
Well, here are some results, using either a homemade Convolutional network or the DnCNN model which uses Conv2d and BatchNorm layers from https://github.com/cszn/DnCNN/blob/master/TrainingCodes/dncnn_pytorch/main_train.py
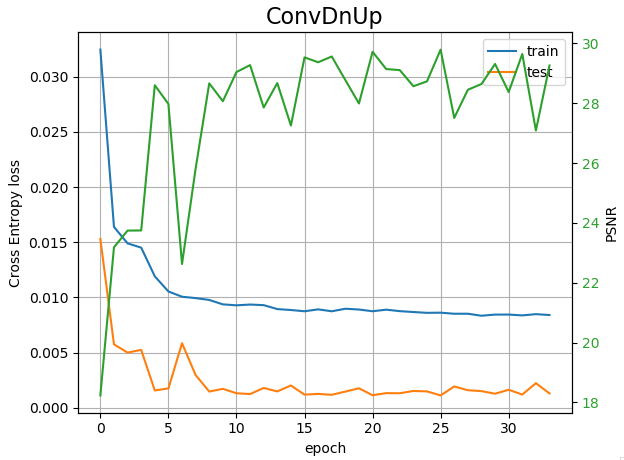
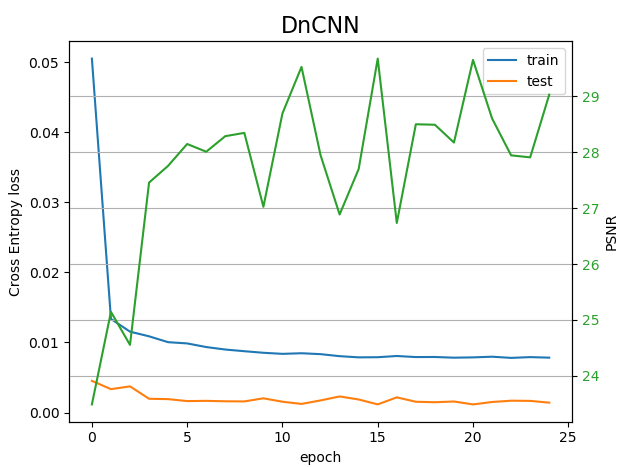
What is puzzling me is why the test loss is so low compared to train loss ??? The two sets are originating to the same larger set of 512x512 images. I use random cropping 64x64 and rotation/flip data augmentation for the train set, in contrast for the test I do not use data augmentation (ie. neither random cropping and flip/rot). The batch_size is 50, 100 for the train and test sets respectively, and the size of the two sets are 5000 and 1000 respectively.
Any idea is welcome.