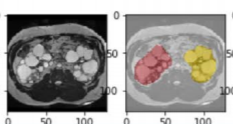
I am creating a model that is performing well for the segmentation problem below:
My question is now I want to now give this model more 3D context and also include the image prior to and after the main image i.e. “neighbors”. Would it make sense to also take the dice loss of these neighbor images with their respective masks, perhaps weighting the loss less than the central image? My primary metric is optimizing the main image segmentation for any given volume. Any feedback is appreciated!
Your approach would thus mean to change the 2D use case to a 3D one, right?
Instead of classifying a single slice you would now consider a small volume of slices and predict all segmentation masks for these slices.
That sounds reasonable, as the depth dimension should also yield useful information besides the spatial dimensions.
Or would you still use the 2D model and just pass multiple slices to the model?
Yes, one idea is making the 2D case a 3D one. I would have to then run inference across a stack of images for the patient, possibly shifting the model over one image at a time and averaging results. To do this, I think simply averaging the loss for each output mask would suffice?
I was also wondering if there was a good way to check consistency across the three image predictions as an input to the model. (I.e. the predictions should have a similar distribution and number of positive pixels should also be similar – the anatomy cannot shift rapidly across a single image).
Curious if you had any pointers or examples of people doing this in PyTorch!
That’s an interesting use case. However, would you like to use 3D modules for it (e.g. nn.Conv3d) or rather a windowed approach?
Really just a wild idea, but for a windowed approach, you could use the predicted classes of the “middle” slice as an additional cross entropy loss for the neighboring slices.
I have no idea, if this would work at all, but might be worth a try.