11179
March 20, 2021, 11:00am
1
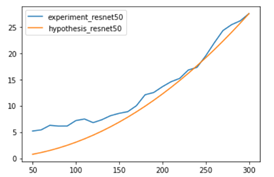
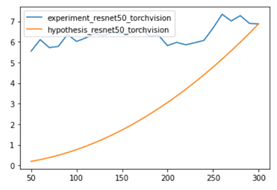
Hello, I’m trying to compare how inference time getting faster by reducing FLOPs through changing input sizes.
What makes the difference?
x-axis showing the length of the input, test by Tensor shape (1, 3, x , x)
github code (with no Fully connected layer and avgpool layer)
torchvsion code (with changing Fully connected layer and avgpool layer to Idenetity layer)
'''ResNet in PyTorch.
For Pre-activation ResNet, see 'preact_resnet.py'.
Reference:
[1] Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
Deep Residual Learning for Image Recognition. arXiv:1512.03385
'''
import torch
import torch.nn as nn
import torch.nn.functional as F
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_planes, planes, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(
in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
show original
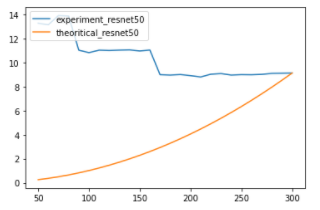
Could you disable cudnn via torch.backends.cudnn.enabled = False and check, if the experimental speed would better fit the theoretical one?
11179
March 22, 2021, 9:47am
4
Whole code, directly can run on colab notebook.
import torchvision
import numpy as np
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
# torch.backends.cudnn.benchmark = False
model = torchvision.models.resnet50(pretrained= False)
model.avgpool = nn.Identity()
model.fc = nn.Identity()
# model = ResNet50()
x_axis = range(50,301, 10)
all_t_resnet =[]
model = model.cuda().eval()
with torch.no_grad():
for i in x_axis:
t = []
for _ in range(100):
start = torch.cuda.Event(enable_timing=True)
end = torch.cuda.Event(enable_timing=True)
size = [i, i]
x= torch.randn(1,3,size[0],size[1]).cuda()
torch.cuda.synchronize()
start.record()
_ = model(x)
end.record()
torch.cuda.synchronize()
measure_t = start.elapsed_time(end)
t.append(measure_t)
all_t_resnet.append(np.mean(t))
theoritic_resnet = (np.array(x_axis)/x_axis[-1])**2*all_t_resnet[-1]
# plt.gca().set_color_cycle(['red', 'green'])
plt.plot(x_axis, all_t_resnet)
plt.plot(x_axis, theoritic_resnet)
plt.legend(['experiment_resnet50', 'theoritical_resnet50'], loc='upper left')
plt.show()
11179
March 22, 2021, 9:53am
5
Thank you for replying
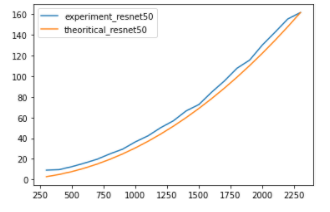
Yes, I did it, but it does not change the result. Below is the result run on colab.
However, as the input size gets bigger, it seems to converge to the experimental line.
(Post images aer run on RTX 2080ti, while this reply images are on colab Tesla P100)
Thanks for the update!
1 Like
11179
March 23, 2021, 1:44pm
7
Oh, I see. Thanks.