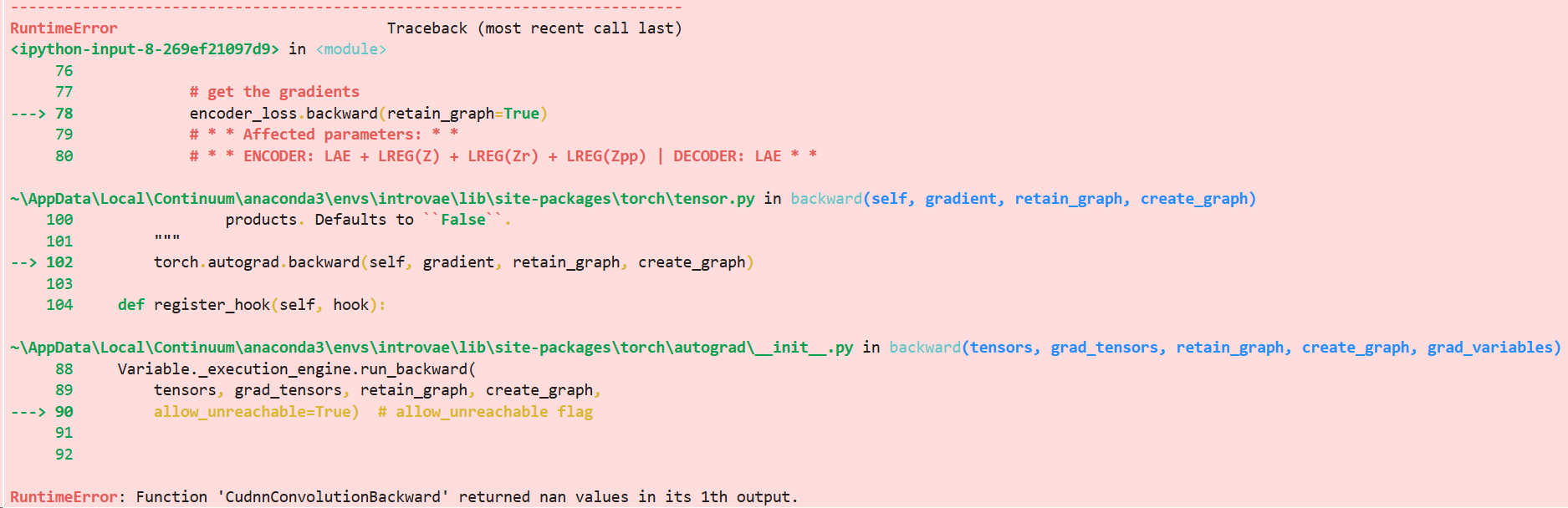
Thank you for suggestions, loading the model with the state dict from working model yields the same issues.
Here is the exception raised by detect_anomaly:
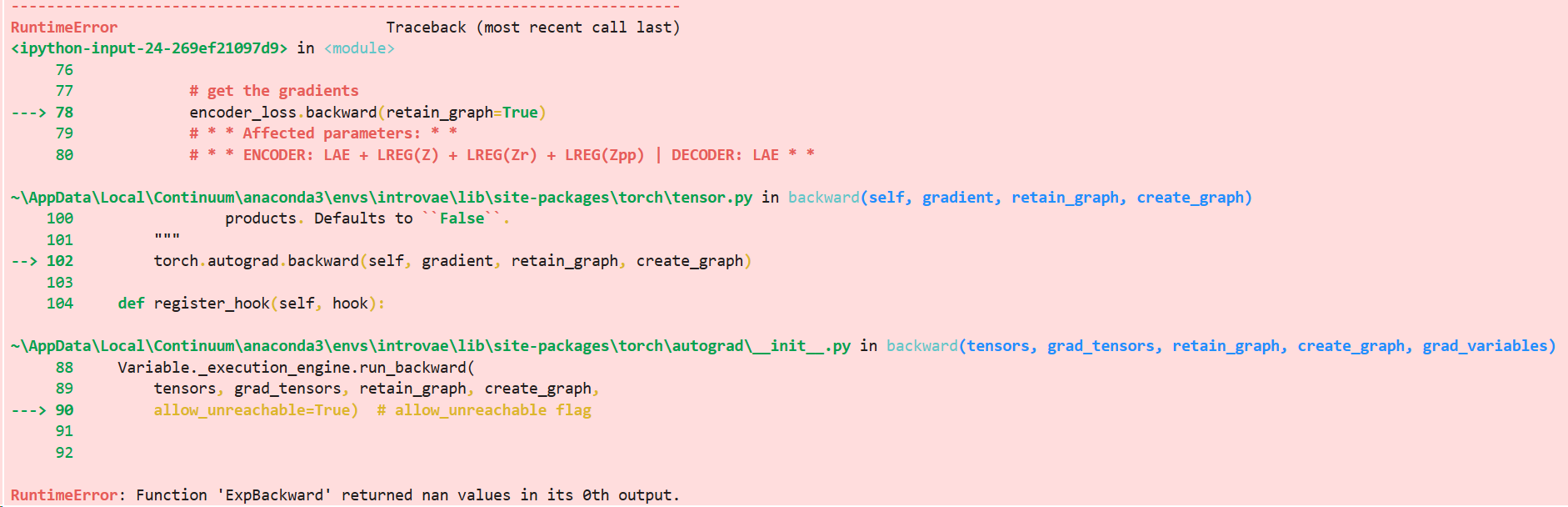
Thank you for suggestions, loading the model with the state dict from working model yields the same issues.
Here is the exception raised by detect_anomaly:
Before looking into it further, to rule out randomness, have you
torch.backends.cudnn.deterministic = TrueEDIT: Another thing to check
Yes, the
LAEand theELossare pretty similar in the first epoch on both machines. I noticed that activations and gradients blow up in the very first batch for no apparent reason,
I’ve seen that before on old PyTorch versions with log_softmax (I think there was a bug fix at some point). Are both machines running PyTorch 1.0?
Hi, I have not, however, the differences are astronomical and I don’t think it is attributed to random seed. Plus as @ptrblck suggested I loaded the state from my working model, while it still produced the same issue.
Hi, I have not, however, the differences are astronomical and I don’t think it is attributed to random seed.
I’ve seen that happen before. Same code runs fine sometimes, sometimes not depending on the shuffling order. Really depends on the architecture, but exploding or vanishing gradient problems can easily accrue if you have long architectures and just one small or big multiplication at some point. Just for comparison purposes, I would at least set cuDNN to deterministic for now to make sure both cards are using the same algorithms to help with the further debugging
Yeah, that’s a good point. I would also try to set all seeds and use deterministic methods first.
Then I would suggest to use the data of the first batch in both scripts to narrow down the difference between both machines.
torch.manual_seed(42)
torch.backends.cudnn.deterministic = True
for both networks on my machine and the work machine. Also, I saved the network state in the working model and loaded it into not working model. Also, I used only 16 same images this time in both models without shuffling.
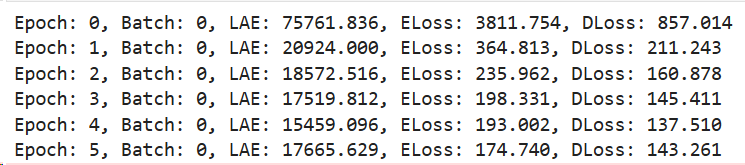
Here is the output from the working model:
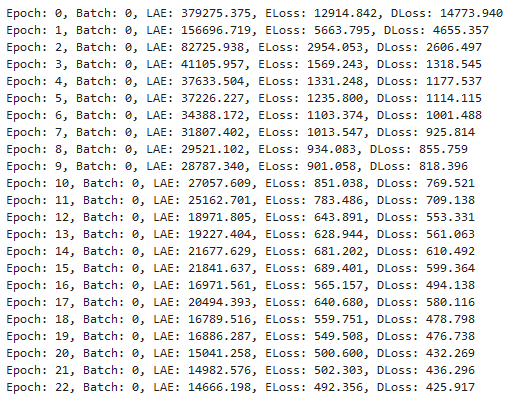
This is the output from the other model:
Here is the output of the detect_anomaly, however, the exception is different sometimes:
Could you disable cuDNN and try it again?
torch.backends.cudnn.enabled = False
@ptrblck So, I unplugged one of the RTX2080Ti, even though I wasn’t using it, and left the other one in. I restarted the machine and ran the same script with no issues occurring (with both cuDNN on and off):
However, I am not sure why the losses are different from the other machine, since we fixed the seed.
That’s interesting. It sounds like an hardware issue then.
Did you install PyTorch via pip/conda or build from source?
Could you compare the versions via print(torch.__version__)?
Both were 1.0.1 installed through conda. So, one of the cards always results in issues running the model, the other one runs just fine (I tried them both separate in different PCIe ports). I am not sure how CUDA processes the information on the device but it seems that something wrong with the GPU and I am going to try to exchange it (not sure if not correctly working CUDA is a legit reason to return a GPU though). Thank you @ptrblck and @rasbt for your help.
hm, I think I remember seeing RTX2080 specific issues regarding elsewhere (not sure if if was in this discussion forum or elsewhere) and just saw this post from november: https://www.pcbuildersclub.com/en/2018/11/broken-gpus-nvidia-apparently-no-longer-sells-the-rtx-2080-ti/
In any case, it may be that your’s may unfortunately be affected. I’d probably also go with the replacement thing now as this appears not to be an unusual case
Yeah, I read they had problems with dying cores in the very beginning, I am going to post on NVIDIA dev forums tomorrow in search of some kind of utility to check the CUDA cores.
just FYI, I just see that there were similar issues here as well
@ptrblck, @rasbt I have a follow up for the issue:
I am running the model on non-faulty GPU and I have noticed that kaiming_normal_ initialization makes my losses go up substantially. However, I had the same behavior of a model with the kaiming_normal_ initialization on my home rig with GTX 1080Ti. Is there a reason why Kaiming normal initialization substantially increases the training loss?
Without kaiming_normal_ initialization:
With kaiming_normal_ initialization:
Is there a reason why Kaiming normal initialization substantially increases the training loss?
No, there shouldn’t be a specific reason for Kaiming/He increasing the training loss – personally, I only notices minor differences. Actually, the default Kaiming He (normal) initialization scheme and PyTorch’s default initialization schemes look relatively similar.
Kaiming (normal) uses:
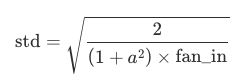
with a=0 by default.
The PyTorch default uses:
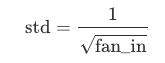
when i see that correctly from
def reset_parameters(self):
stdv = 1. / math.sqrt(self.weight.size(1))
self.weight.data.uniform_(-stdv, stdv)
if self.bias is not None:
self.bias.data.uniform_(-stdv, stdv)
But since the sqrt is in the denominator, it can be much larger. So you probably want to lower your learning rate when using kaiming_normal_. Would be curious to hear what happens if you do that. Maybe choose the learning rate as follows:
learning_rate_before * default_std(fan_in) = new_learning_rate * kaiming(fan_in)
=> earning_rate_before * default_std(fan_in) / kaiming(fan_in) = new_learning_rate
Would be curious to hear what you find…
Thank you for your suggestion, I will try to do this on my simple toy model which I have built yesterday, which has exactly same problem for some reason; I have seen the increase in the training loss for up to x100 times.
The issue was resolved by itself, not sure what happened 
I had a very similar problem with RTX 2080 Ti. I ran the same code on three different GPUs - GTX 1050, TITAN X and RTX 2080Ti. The training process goes fine on GTX 1050 and TITAN X, but on RTX 2080Ti the loss decreases for a few steps and finally raises fast up to a random guessing level (Accuracy achieves a random efficiency). Sometimes I observed NaNs, but not often. In my case, the problem was my own loss function, which I implemented as follow:
def cross_entropy_with_one_hots(input, target):
logsoftmax = torch.nn.LogSoftmax(dim=1)
return torch.mean(torch.sum(- target * logsoftmax(input), 1))
Using PyTorch’s torch.nn.CrossEntropyLoss with labels instead one hots, the training process on all three GPUs goes fine. I am guessing the problems is numerical properties of my function, but I am wondering why it works on GTX 1050 and TITAN X, but not on RTX 2080Ti?
Using torch.nn.CrossEntropyLoss solves the problem, but makes impassible mixuping or label smoothing.
In our case it was a faulty GPU that we sent back to the manufacturer for replacement. When the replacement came, the model worked just like it was intended to.