I’ve been playing around with the autograd engine, attempting to “manually” update a network’s parameters via the autograd mechanism, replicating SGD. However, in doing so, I’ve got different results compared to the automatic/conventional way of updating a network’s parameters (using opt.step()). I’ve had the following settings to ensure reproducibility when running the same network using the different updating schemes:
device = torch.device('cuda')
torch.cuda.empty_cache()
torch.manual_seed(0)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
np.random.seed(0)
The network used was a simple multi-layer FFN (MNIST classification):
class Model(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Sequential(nn.Linear(784, 1440, bias=False), nn.BatchNorm1d(1440), nn.ReLU())
self.fc2 = nn.Sequential(nn.Linear(1440, 1440, bias=False), nn.BatchNorm1d(1440), nn.ReLU())
self.fc3 = nn.Sequential(nn.Linear(1440, 784, bias=False), nn.BatchNorm1d(784), nn.ReLU())
self.fc4 = nn.Sequential(nn.Linear(784, 784, bias=False), nn.BatchNorm1d(784), nn.ReLU())
self.fc5 = nn.Linear(784, 10)
def forward(self, x):
return nn.Sequential(*list(self.children()))(x)
Updating the network using the “manual” way was done in the following manner:
m2 = Model().to(device)
for e in trange(epochs):
for x, y in train_loader:
x, y = x.to(device, non_blocking=True), y.to(device, non_blocking=True)
loss = F.cross_entropy(m2(x), y)
grad = torch.autograd.grad(loss, m2.parameters())
for p, g in zip(m2.parameters(), grad):
p.data -= LR * g
While updating the network using the “automatic/conventional” way was as follows:
m1 = Model().to(device)
opt = torch.optim.SGD(m1.parameters(), lr=LR)
for e in trange(epochs):
for x, y in train_loader:
x, y = x.to(device, non_blocking=True), y.to(device, non_blocking=True)
loss = F.cross_entropy(m1(x), y)
loss.backward()
opt.step()
opt.zero_grad()
The learning rates and epochs used are the same in both cases.
Here is a visualization of the results I got:
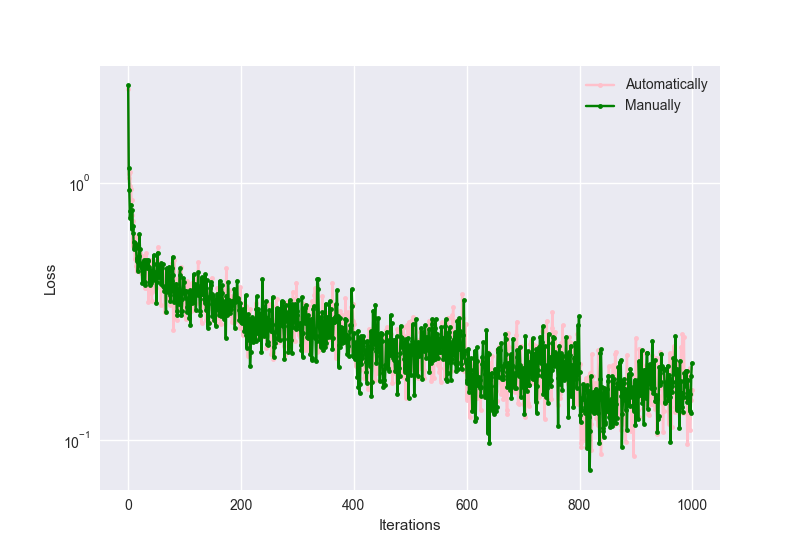
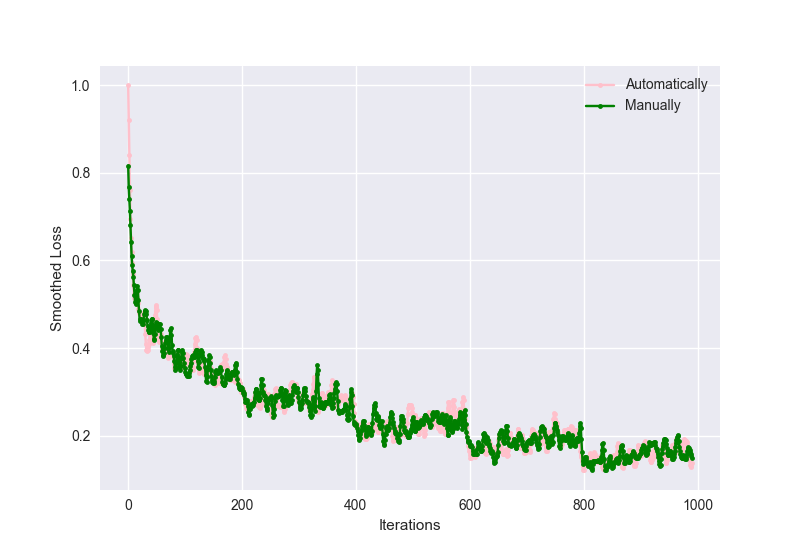
While the accuracies were:
Accuracy (Automatic): 88.0%
Accuracy (Manual): 86.7%
Can someone explain to me why these differences arise? Is there something extra going on behind the hood?