Hey,
I am working on a yolo implementation that has similar parts as the implementation by ayooshkathuria.
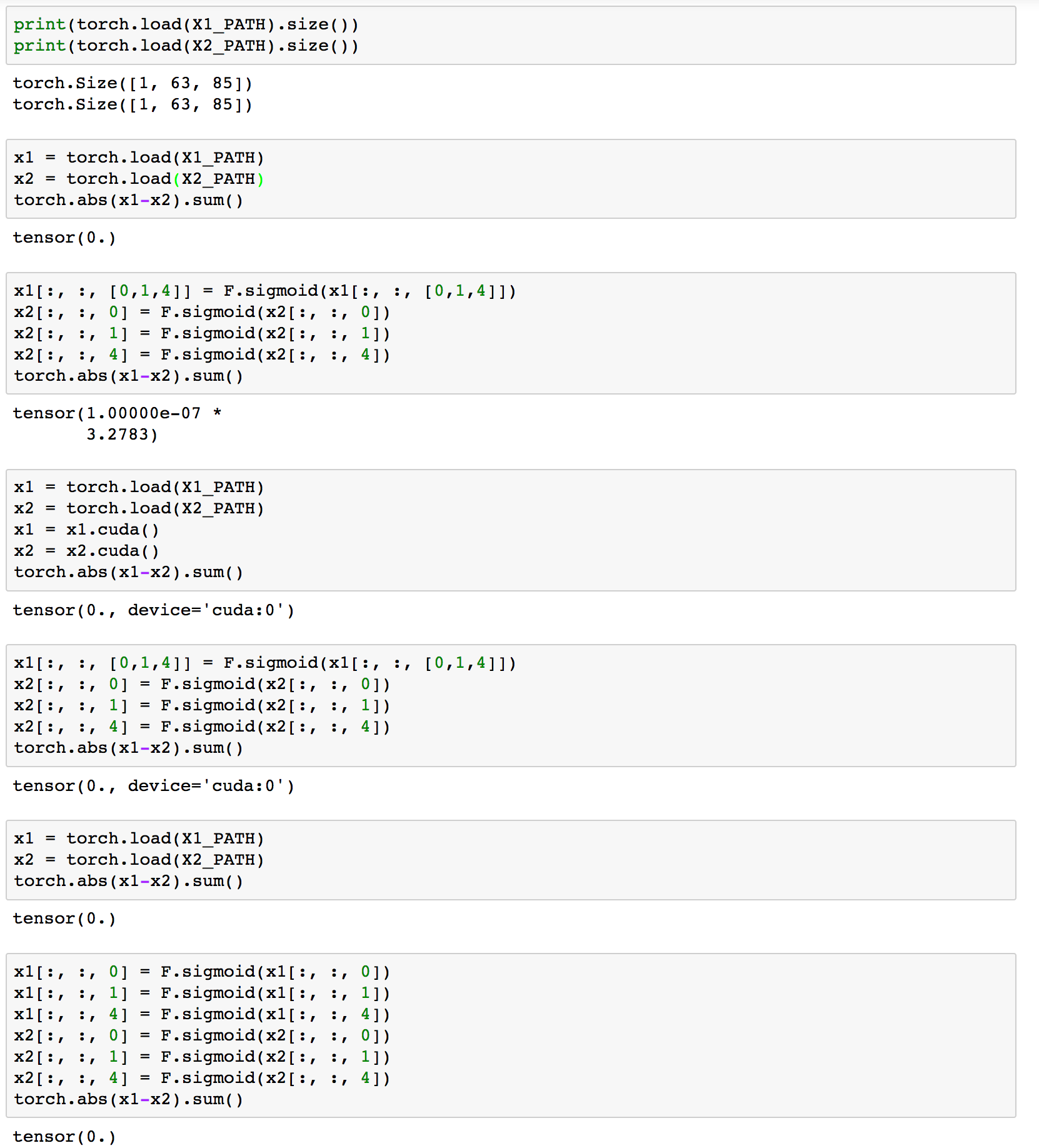
In one of those places he sigmoids a number of elements in a tensor by doing it 3 times for 3 different indexes.
I did the same operation with advanced indexing. However, I noticed that the results were different from his so I did some tests
I got the tensor from my implementation (x1) and the tensor from his implementation (x2) just before the step that made them have slightly different values. I saved these tensors for testing and ran the tests in a notebook.
As you can see, the tensors have the exact same values before the sigmoid operation is performed. I could only replicate the results with these tensors. I tried creating x1 with torch.rand and then copying it to x2 but then the results are correct. I also tried using just x1 where x2 = x1.detach() but those results were also correct.
The incorrect results only show when using the CPU and advanced indexing.
The difference is not large enough to affect the results. I am just curious as to why this happens. Am I using advanced indexing incorrectly?
The 1e-07 difference is probably just floating point error. If you want even more precise values then you should use DoubleTensor instead of FloatTensor.
Yea the error is no problem as its extremely small, I was a bit curious for why it happens only when using advanced indexing but it doesnt really matter!
Another question:
Lets say I want to sigmoid index [0, 1, 4] and the slice [6:]. Is there a speed difference between doing it all in one operation like this:
x = ... # vector
indices = [0, 1, 4] + list(range(6, x.size(0)))
x[indices] = F.sigmoid(x[indices])
or like this:
x = ... # vector
indices = [0, 1, 4]
x[indices] = F.sigmoid(x[0, 1, 4])
x[6:] = = F.sigmoid(x[6:])
Or is the operation on advanced indexing the same as with slicing, ie:
x[:4] = F.sigmoid(x[:4])
is the same as
x[[0, 1, 2, 3]] = F.sigmoid(x[[0, 1, 2, 3]])
I know these produce the same result but I am wondering if they are performed differently “under the hood”. If slices are more effective as data might be contiguous, are a list of indexes such as [0, 1, 2, 3] viewed as a slice?
I know its quite a weird question and I could not find an answer for it. I dont think it makes any noticeable difference for my implementation, this is more out of curiosity.