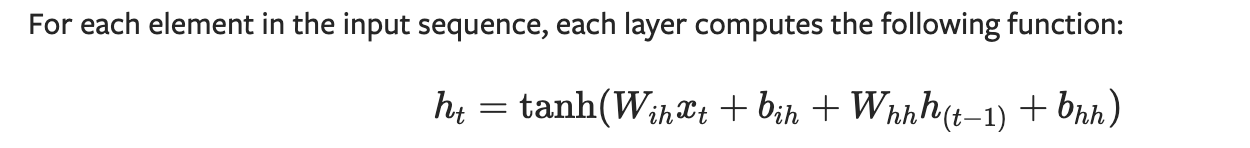For instance I have this rnn:
rnn = torch.nn.RNN(2, 2, 1, batch_first = True)
and I have input of:
x = torch.tensor([[[1,1], [2,2], [3,3]], [[2,2], [3,3], [4,4]], [[4,4], [5,5], [6,6]]])
My model shows that it have this type of parameters:
weight_ih_l0 tensor([[-0.1641, -0.6958],
[ 0.1889, 0.4084]])
weight_hh_l0 tensor([[ 0.0063, -0.5073],
[-0.2890, -0.5403]])
bias_ih_l0 tensor([-0.0039, -0.2850])
bias_hh_l0 tensor([ 0.5279, -0.1149])
If hidden is initialized as none my output will be like:
hidden = None
out, hidden = rnn(x.float(), hidden)
out
tensor([[[-0.3238, 0.1948],
[-0.8609, 0.6544],
[-0.9835, 0.8584]],
[[-0.8324, 0.6611],
[-0.9836, 0.8553],
[-0.9976, 0.9480]],
[[-0.9941, 0.9633],
[-0.9996, 0.9821],
[-0.9999, 0.9945]]]
So this RNN hidden state have this formula:
h_t = tanh(w_{ih} * x_t + b_{ih} + w_{hh} * h_{(t-1)} + b_{hh})
but w_{ih} will have shape 2X2 and x_t will have shape 1X2 (for instance first input [1,1]), how then they multiple and work? Or is it work differently in pytorch?
I am asking this question because I tried to recreate this in numpy, but this call error due to inappropriate dimensions in this part, which is right from lin. alg. point of view.
h_t = numpy.tanh(hh@hidden + ih@numpy.matrix([1,1]) + bias_ih + bias_hh)