I define a simple network and train it.
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.optim.lr_scheduler import MultiStepLR
from torch.utils.data import random_split, Dataset, DataLoader
class BaseNet(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.BatchNorm1d(num_features=1, momentum=0.1, eps=2e-5),
nn.Conv1d(in_channels=1, out_channels=4, kernel_size=1, bias=False),
nn.BatchNorm1d(num_features=4, momentum=0.1, eps=2e-5),
nn.PReLU(num_parameters=4),
nn.Conv1d(in_channels=4, out_channels=16, kernel_size=3, bias=False, padding=1),
nn.BatchNorm1d(num_features=16, momentum=0.1, eps=2e-5),
nn.PReLU(num_parameters=16),
nn.Conv1d(in_channels=16, out_channels=4, kernel_size=3, bias=False, padding=1),
nn.BatchNorm1d(num_features=4, momentum=0.1, eps=2e-5),
nn.PReLU(num_parameters=4),
nn.Conv1d(in_channels=4, out_channels=1, kernel_size=1, bias=False),
)
def forward(self, x):
return self.net(x)
class DataSet(Dataset):
def __init__(self, x, y):
super().__init__()
self.x = torch.tensor(x).float()
self.y = torch.tensor(y).float()
def __len__(self):
return self.x.shape[0]
def __getitem__(self, item):
return self.x[item], self.y[item]
def train(train_data, val_data):
def ridiculous_val(n, v):
with torch.no_grad():
n = n.eval()
m = list()
for a, b in v:
p = n(a.cuda())
m.append(F.l1_loss(p, b.cuda()).item())
return np.mean(m)
net = BaseNet()
net = net.cuda()
opt = optim.SGD(net.parameters(), lr=0.1, momentum=0.9, weight_decay=0.9)
scheduler = MultiStepLR(opt, [500, 800, 1100, 1400, 1700], gamma=0.1)
loss = nn.L1Loss()
min_loss = np.float("inf")
n_batch = 0
net = net.train()
for epoch in range(0, 99999):
for x, y in train_data:
x, y = x.cuda(), y.cuda()
opt.zero_grad()
pred = net(x)
loss_val = loss(y, pred)
loss_val.backward()
opt.step()
print("[{}], {}".format(epoch, loss_val.item()))
n_batch += 1
if n_batch % 100 == 0:
_loss = ridiculous_val(net, val_data)
print("min ", _loss, min_loss)
if _loss < min_loss:
min_loss = _loss
print("saving...", min_loss)
torch.save(net.state_dict(), "net.pth")
net = net.train()
scheduler.step(epoch)
def val(some_data):
net = BaseNet()
net = net.cuda()
state_dict = torch.load("net.pth")
net.load_state_dict(state_dict)
pred = np.empty(some_data.shape)
for i, x in enumerate(some_data):
pred[i, ...] = net(torch.from_numpy(x[None, :, :]).float().cuda()).cpu().detach().numpy().squeeze()
return pred
if __name__ == '__main__':
dst = np.load("diff.npy") # shape (12000, 512)
src = np.load("src.npy") # shape (12000, 512)
src, dst = src[:, None, :], dst[:, None, :]
data = DataSet(src, dst)
train_len, val_len = int(len(data) * 0.5), int(len(data) * 0.2)
test_len = len(data) - train_len - val_len
train_set, val_set, test_set = random_split(data, [train_len, val_len, test_len])
train_set = DataLoader(train_set, batch_size=1024, shuffle=True, pin_memory=True, drop_last=False)
val_set = DataLoader(val_set, batch_size=1024, shuffle=False, pin_memory=True, drop_last=False)
train(train_set, val_set)
I observed that
epoch 33
[param for param in net.parameters()][2].abs().max() is 1e-6
[param for param in net.parameters()][2].grad.abs().max() is 7e-6.
loss is 0.263
epoch 67
[param for param in net.parameters()][2].abs().max() is 6e-11
[param for param in net.parameters()][2].grad.abs().max() is 2e-11
loss is 0.264
epoch 134
[param for param in net.parameters()][2].abs().max() is 3e-20
[param for param in net.parameters()][2].grad.abs().max() is 2e-20
loss is 0.264
After epoch 324, both of parameters and grad are 0, loss is 0.263.
Does it mean that this network think that function f(x) = 0 is the best mapping function for my data?
Or I do something wrong?
Here are two examples of my data, specifically, they are the output of another image encode network.
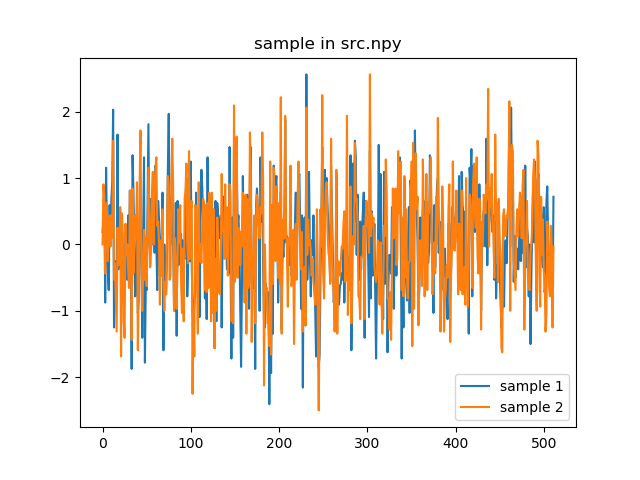
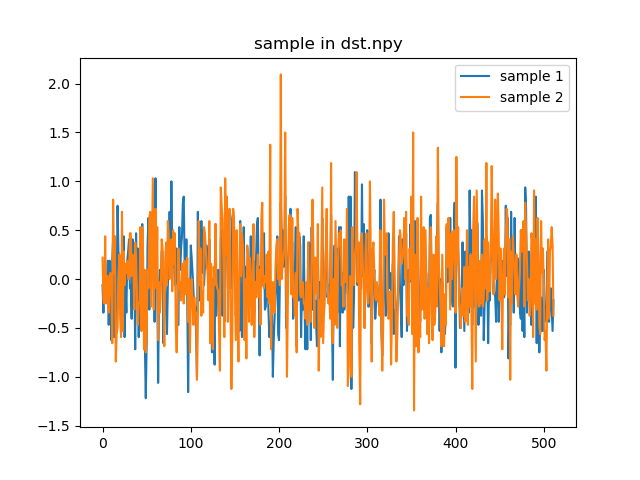
Maybe this is a stupid question, but I am really looking forward to getting some suggestions, thanks.