Hello guys I am new to pytorch and I am trying to create the following neural network:
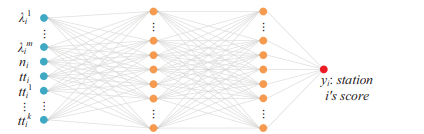
http://urban-computing.com/pdf/UbiComp2019JiZheng.pdf
The trick is that I have 5 copies of them and in the end I am joining them with a softmax function.
Am I doing this correctly? I do not have much experience with strange neural networks and how autograd works in them.
The input is ([batch_size, neural network number, input_state])
def net(torch.nn.Module):
def init(self, bases, state_space, action_space, n_hidden = 20):
super(policy_estimator,self).init()
self.base11 = torch.nn.Linear(state_space,n_hidden)
self.base12 = torch.nn.Linear(n_hidden, n_hidden)
self.base13 = torch.nn.Linear(n_hidden, 1)
self.base21 = torch.nn.Linear(state_space,n_hidden)
self.base22 = torch.nn.Linear(n_hidden, n_hidden)
self.base23 = torch.nn.Linear(n_hidden, 1)
self.base31 = torch.nn.Linear(state_space,n_hidden)
self.base32 = torch.nn.Linear(n_hidden, n_hidden)
self.base33 = torch.nn.Linear(n_hidden, 1)
self.base41 = torch.nn.Linear(state_space,n_hidden)
self.base42 = torch.nn.Linear(n_hidden, n_hidden)
self.base43 = torch.nn.Linear(n_hidden, 1)
self.base51 = torch.nn.Linear(state_space,n_hidden)
self.base52 = torch.nn.Linear(n_hidden, n_hidden)
self.base53 = torch.nn.Linear(n_hidden, 1)
# Activation functions
self.activation_tanh = torch.nn.Tanh()
self.activation_softmax = torch.nn.Softmax(dim=1)
def forward(self, x):
out1 = self.activation_tanh(self.base11(x[:,0,:]))
out1 = self.activation_tanh(self.base12(out1))
out1 = self.base13(out1)
out2 = self.activation_tanh(self.base21(x[:, 1, :]))
out2 = self.activation_tanh(self.base22(out2))
out2 = self.base23(out2)
out3 = self.activation_tanh(self.base31(x[:, 2, :]))
out3 = self.activation_tanh(self.base32(out3))
out3 = self.base33(out3)
out4 = self.activation_tanh(self.base41(x[:, 3, :]))
out4 = self.activation_tanh(self.base42(out4))
out4 = self.base43(out4)
out5 = self.activation_tanh(self.base51(x[:, 4, :]))
out5 = self.activation_tanh(self.base52(out5))
out5 = self.base53(out5)
score_torch=torch.stack([out1.squeeze(dim=0),out2.squeeze(dim=0),out3.squeeze(dim=0), out4.squeeze(dim=0), out5.squeeze(dim=0)], dim=1)
action_probs = self.activation_softmax(score_torch)
return action_probs
Thanks so much!