I am trying to make two branches in the network as shown in picture below. L1 are layers in the original model. And L2 are cloned layers from L1. These are fully connected layers. I can add layers by nn.Sequential? Moreover, how I can train only L2 layers in the network while L1 layers should not be trained? It is like how I can train network with either L2 branch or L1 branch separately.
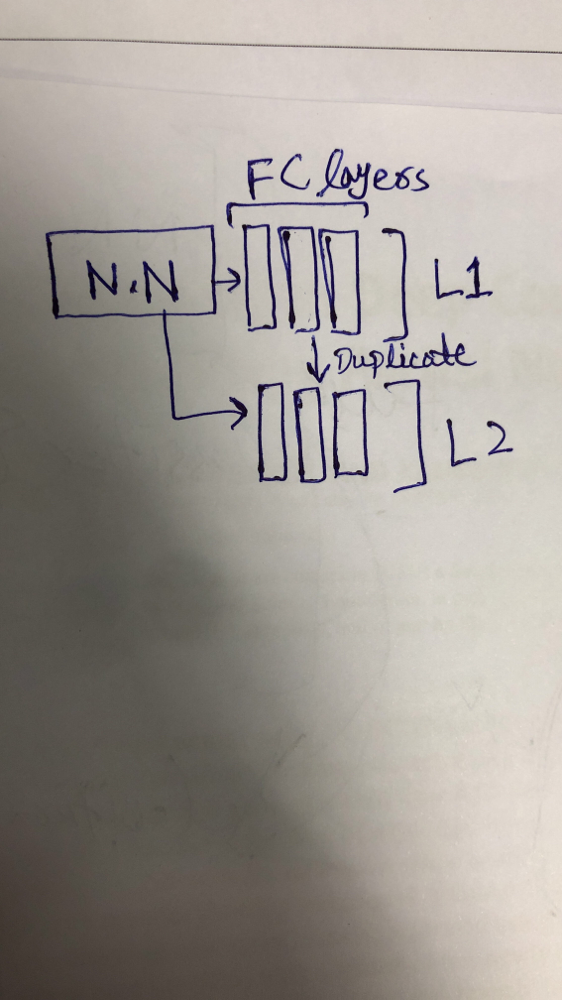
To add layers in the nn.Sequential, you can create a class that inherits nn.Sequential, or you can pass in the modules directly as parameters (like here: torch.nn.Sequential).
Re your second question, I think one approach is to set the L1 layers to be .requires_grad=False.
I have tried to put two different classifiers like this:
(classifier): Sequential(
(0): Sequential(
(0): Linear(in_features=1280, out_features=512, bias=True)
(1): Tanh()
(2): Linear(in_features=512, out_features=256, bias=True)
(3): Tanh()
(4): Linear(in_features=256, out_features=128, bias=True)
(5): Tanh()
(6): Linear(in_features=128, out_features=200, bias=True)
)
(1): Sequential(
(0): Linear(in_features=1280, out_features=512, bias=True)
(1): Tanh()
(2): Linear(in_features=512, out_features=256, bias=True)
(3): Tanh()
(4): Linear(in_features=256, out_features=128, bias=True)
(5): Tanh()
(6): Linear(in_features=128, out_features=29, bias=True)
)
)
How I can skip classifier[0] or classifier[1] during training the model?
I’m sure there is a better way, but I thought you could try separating them, then pas in a pointer in the forward method.
For example:
import torch
class NeuralNetwork(torch.nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.add_module('L1', torch.nn.Sequential(
torch.nn.Linear(1280, 512, True),
torch.nn.Tanh(),
torch.nn.Linear(512, 256, True),
torch.nn.Tanh(),
torch.nn.Linear(256, 128, True),
torch.nn.Tanh(),
torch.nn.Linear(128, 200, True)
)
self.add_module('L2', torch.nn.Sequential(
torch.nn.Linear(1280, 512, True),
torch.nn.Tanh(),
torch.nn.Linear(512, 256, True),
torch.nn.Tanh(),
torch.nn.Linear(256, 128, True),
torch.nn.Tanh(),
torch.nn.Linear(128, 29, True)
)
def forward(self, x, classifier):
if classifier == 0:
return self.L1(x)
elif classifier == 1:
return self.L2(x)
Then in your training loop, you could just flag in the classifier into the model.(x, classifier).