Thank you, Sir. You are a life saver. 
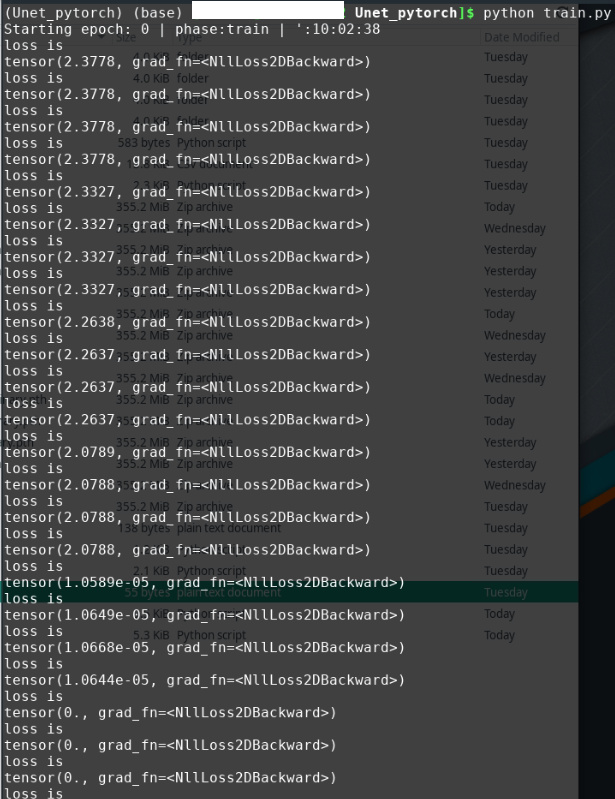
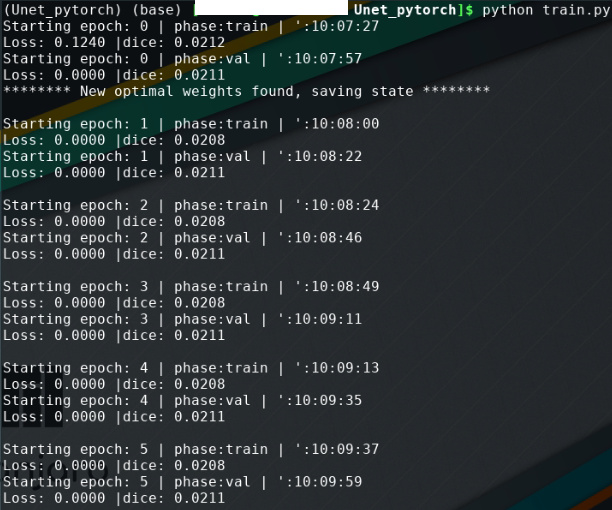
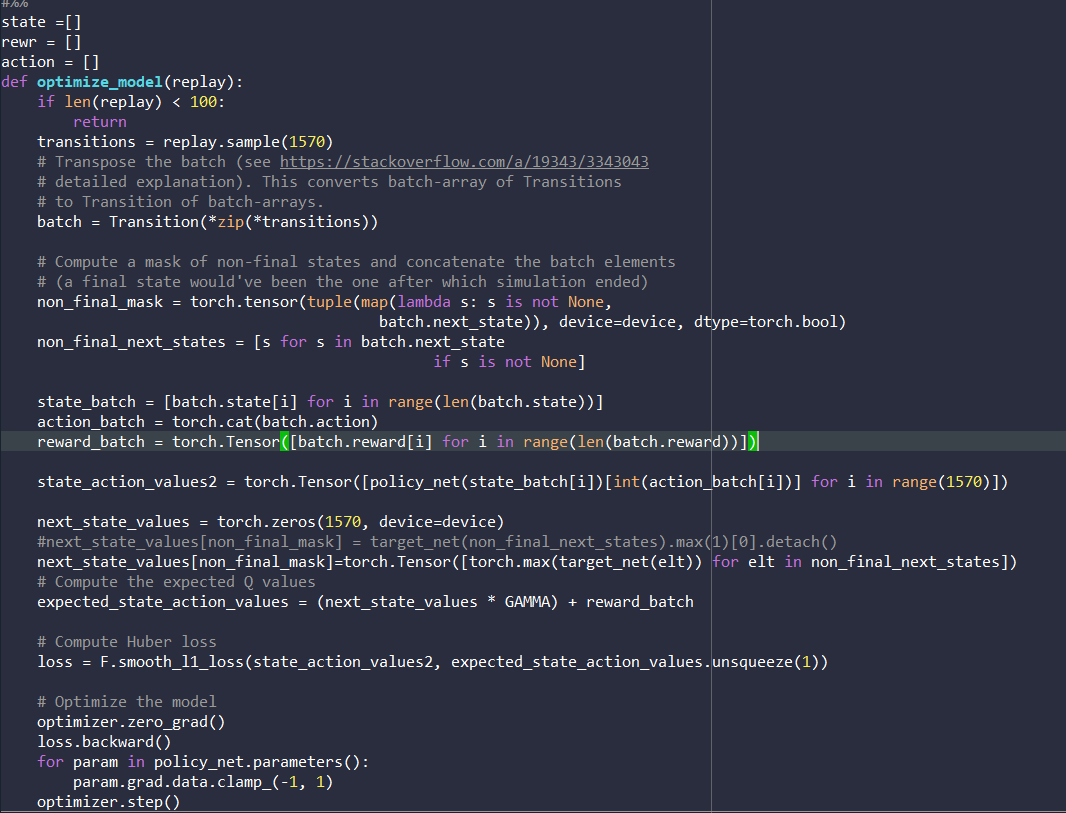
I modified these lines as you suggested and it does work now without error. But when I evaluate the linear model for speaker identification, the speaker_scores seems to be wrong. I am not sure whether it is related with the error you help me fixed.
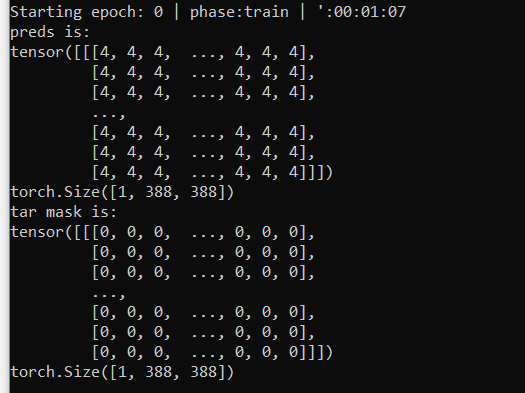
As the output of speaker_scores shows below, somehow the first number in each column always is the largest. When I need to get index of the largest score with tensor.argmax, I got zeros all the time. Does the output of speaker_scores look right? Do you have any suggestions here? I really appreciate your help!!!
def evaluate_linear_model(config, apc_model, linear_model, criterion, device, data_loader):
linear_model.eval()
losses = []
with torch.no_grad():
for batch_x, batch_l, batch_a in data_loader:
batch_x, batch_l, batch_a = setup_inputs(config, batch_x, batch_l, batch_a, device)
loss, speaker_scores = pass_inputs_through_model(config, apc_model, linear_model, criterion, batch_x, batch_l,batch_a,device)
losses.append(loss.item())
speaker_class_predictions = torch.argmax(speaker_scores, dim=1)
# print("speaker_scores", speaker_scores)
# print("speaker_class_predictions",speaker_class_predictions)
# find positions where we have a correct prediction
correct_pred = (speaker_class_predictions == batch_a)
lengths_mask = get_lengths_mask(correct_pred, batch_l, device)
masked_correct_pred = lengths_mask * correct_pred
correct = 0 # numerator - keep track of number of errors
total_speakers = 0 # denominator - keep track of total number of classes
# get number of correct predictions
correct += masked_correct_pred.sum().item() # to_all_ALL is int datatype
# get total number of frames
total_speakers += batch_a.size(1)
ser= 100 * ((total_speakers - correct) / total_speakers)
return ser, losses
def setup_inputs(config, batch_x, batch_l, batch_a, device):
_, indices = torch.sort(batch_l, descending=True)
batch_x = Variable(batch_x[indices]).to(device)
batch_l = Variable(batch_l[indices]).to(device)
batch_a = Variable(batch_a[indices]).to(device)
return batch_x, batch_l, batch_a
def pass_inputs_through_model(config, apc_model, linear_model, criterion, batch_x, batch_l, batch_a, device):
_, internal_rep = apc_model.forward(batch_x, batch_l) # last RNN layer
internal_rep = internal_rep.detach()
speaker_scores = linear_model(internal_rep)
loss_not_reduced = criterion(speaker_scores, batch_a)
lengths_mask = get_lengths_mask(loss_not_reduced, batch_l, device)
loss_not_reduced_masked = lengths_mask * loss_not_reduced
loss = loss_not_reduced_masked.mean()
return loss, speaker_scores
Here is the output of speaker_scores (size:[16, 1600, 40]) and speaker_class_predictions(size:[16, 40]) at the first iteration.
speaker_scores tensor([[[ 8.0500e+00, 8.0797e+00, 8.0590e+00, ..., 7.9894e+00,
7.9996e+00, 8.0968e+00],
[ 6.5967e+00, 6.6829e+00, 6.4854e+00, ..., 6.5828e+00,
6.5779e+00, 6.6216e+00],
[ 3.8995e+00, 4.0742e+00, 3.8886e+00, ..., 3.8872e+00,
3.9899e+00, 3.9925e+00],
...,
[-3.8165e+00, -3.7231e+00, -3.8339e+00, ..., -3.5709e+00,
-3.6196e+00, -3.8674e+00],
[-3.3267e+00, -3.2683e+00, -3.3269e+00, ..., -3.0943e+00,
-3.1706e+00, -3.3947e+00],
[-3.9622e+00, -3.8175e+00, -3.9419e+00, ..., -3.6931e+00,
-3.7702e+00, -4.0186e+00]],
[[ 6.9792e+00, 6.9930e+00, 6.9780e+00, ..., 6.9057e+00,
6.8974e+00, 6.9623e+00],
[ 6.3637e+00, 6.4508e+00, 6.2607e+00, ..., 6.2922e+00,
6.3237e+00, 6.3503e+00],
[ 4.3157e+00, 4.4286e+00, 4.2575e+00, ..., 4.2260e+00,
4.2711e+00, 4.3420e+00],
...,
[ 5.4524e-03, 2.4385e-02, -3.9649e-02, ..., -2.8054e-02,
2.8421e-03, 3.4010e-02],
[ 5.4524e-03, 2.4385e-02, -3.9649e-02, ..., -2.8054e-02,
2.8421e-03, 3.4010e-02],
[ 5.4524e-03, 2.4385e-02, -3.9649e-02, ..., -2.8054e-02,
2.8421e-03, 3.4010e-02]],
[[ 7.1278e+00, 7.1513e+00, 7.1129e+00, ..., 7.0446e+00,
7.0547e+00, 7.1034e+00],
[ 6.4023e+00, 6.4507e+00, 6.2547e+00, ..., 6.3206e+00,
6.3188e+00, 6.3049e+00],
[ 3.7676e+00, 3.9320e+00, 3.7099e+00, ..., 3.6738e+00,
3.7673e+00, 3.8048e+00],
...,
[ 5.4524e-03, 2.4385e-02, -3.9649e-02, ..., -2.8054e-02,
2.8421e-03, 3.4010e-02],
[ 5.4524e-03, 2.4385e-02, -3.9649e-02, ..., -2.8054e-02,
2.8421e-03, 3.4010e-02],
[ 5.4524e-03, 2.4385e-02, -3.9649e-02, ..., -2.8054e-02,
2.8421e-03, 3.4010e-02]],
...,
[[ 7.9684e+00, 7.9946e+00, 7.9834e+00, ..., 7.9156e+00,
7.9113e+00, 8.0028e+00],
[ 6.1155e+00, 6.2138e+00, 6.0246e+00, ..., 6.1267e+00,
6.1100e+00, 6.1350e+00],
[ 3.3304e+00, 3.5016e+00, 3.3533e+00, ..., 3.3398e+00,
3.4059e+00, 3.3948e+00],
...,
[ 5.4524e-03, 2.4385e-02, -3.9649e-02, ..., -2.8054e-02,
2.8421e-03, 3.4010e-02],
[ 5.4524e-03, 2.4385e-02, -3.9649e-02, ..., -2.8054e-02,
2.8421e-03, 3.4010e-02],
[ 5.4524e-03, 2.4385e-02, -3.9649e-02, ..., -2.8054e-02,
2.8421e-03, 3.4010e-02]],
[[ 8.1056e+00, 8.1097e+00, 8.1152e+00, ..., 8.0462e+00,
8.0314e+00, 8.1114e+00],
[ 6.5150e+00, 6.6362e+00, 6.4300e+00, ..., 6.5414e+00,
6.4932e+00, 6.5473e+00],
[ 3.7579e+00, 3.9144e+00, 3.7434e+00, ..., 3.8008e+00,
3.8159e+00, 3.8016e+00],
...,
[ 5.4524e-03, 2.4385e-02, -3.9649e-02, ..., -2.8054e-02,
2.8421e-03, 3.4010e-02],
[ 5.4524e-03, 2.4385e-02, -3.9649e-02, ..., -2.8054e-02,
2.8421e-03, 3.4010e-02],
[ 5.4524e-03, 2.4385e-02, -3.9649e-02, ..., -2.8054e-02,
2.8421e-03, 3.4010e-02]],
[[ 8.3452e+00, 8.3642e+00, 8.3595e+00, ..., 8.2681e+00,
8.2715e+00, 8.4071e+00],
[ 6.8510e+00, 6.9509e+00, 6.7642e+00, ..., 6.8221e+00,
6.7819e+00, 6.9030e+00],
[ 4.1307e+00, 4.2837e+00, 4.1108e+00, ..., 4.1373e+00,
4.1427e+00, 4.2269e+00],
...,
[ 5.4524e-03, 2.4385e-02, -3.9649e-02, ..., -2.8054e-02,
2.8421e-03, 3.4010e-02],
[ 5.4524e-03, 2.4385e-02, -3.9649e-02, ..., -2.8054e-02,
2.8421e-03, 3.4010e-02],
[ 5.4524e-03, 2.4385e-02, -3.9649e-02, ..., -2.8054e-02,
2.8421e-03, 3.4010e-02]]])
speaker_class_predictions tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] .....