Yes, generally if you “leave” PyTorch, i.e. use another library such as numpy, Autograd won’t be able to track these operations and thus the tensor would be detached (you could write a custom autograd.Function and provide the forward and backward method manually).
Also, operations on integers are not differentiable (such as torch.argmax). Besides that you could check derivatives.yaml for the not_implemented keyword.
1 Like
@ptrblck
In my data prepare function, I want to resize the samples before feeding them to the model for training.
I found if I added the resizer then got:
RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
But if I commented out the resizer line, it will run successfully. Is there any ops in resizer that the pyTorch doesn’t like?
Thanks.
class BtsDataLoader(object):
def __init__(self, args, mode):
if mode == 'train':
self.training_samples = DataLoadPreprocess(args, mode, transform=preprocessing_transforms(mode))
if args.distributed:
self.train_sampler = torch.utils.data.distributed.DistributedSampler(self.training_samples)
else:
self.train_sampler = None
self.data = DataLoader(self.training_samples, args.batch_size,
shuffle=(self.train_sampler is None),
num_workers=args.num_threads,
pin_memory=True,
sampler=self.train_sampler)
class DataLoadPreprocess(Dataset):
....
def __getitem__(self, idx):
image, pattern_gt = self.random_crop(image, depth_gt)
image, pattern_gt = self.resizer(image, pattern_gt , self.args.input_height, self.args.input_width)
def resizer(self, img, depth, height, width):
dim = (width, height)
img = cv2.resize(img, dim, interpolation = cv2.INTER_AREA)
depth = cv2.resize(depth, dim, interpolation = cv2.INTER_AREA)
depth_show = np.where(depth < 1e-3, depth * 0, depth)
invalid_mask = (depth_show==0)
# depth_show = 1/depth_show
depth_min = np.nanmin(depth_show)
depth_max = np.nanmax(depth_show)
bits = 1
max_val = (2**(8*bits))-1
if depth_max - depth_min !=0:
depth_map = max_val * (depth_show - depth_min) / (depth_max - depth_min)
# depth_map = (depth_show - depth_min) / (depth_max - depth_min)
else:
depth_map = 0
depth_map_show = np.where(invalid_mask, 0, 255 - depth_map.astype('uint8'))
# cv2.imwrite("after_resize.png", depth_map_show)
depth = np.expand_dims(depth_map_show, 2)
return img, depth
resizer is using numpy operations, so these operations won’t be tracked as described before.
If you would need to calculate the gradients for the input to resizer, you would either have to write a custom backward method or use PyTorch operations for it.
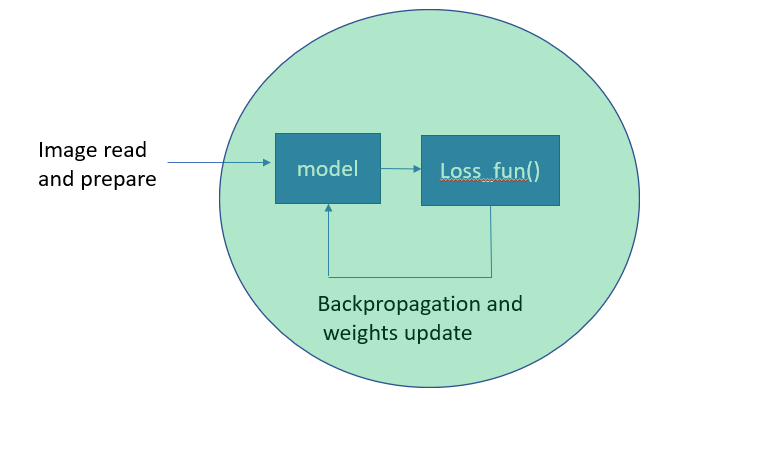
My prior understanding is if the detach() only happens in the green area the above issue will happen.
Do that mean in the image prepare stage the detach() from the graph will also happen if we use NumPy ops (e.g. resizing)?
Thanks
If you don’t need gradients in the input image (before the processing is applied), the error shouldn’t be raised.
Could you post an executable code snippet to reproduce this issue?
Sorry. I can’t post the code here.
But found another thing.
In this loss function if call the depth_norm() and plus the resizer the issue will happen.
If git rid of depth_norm(), i.e. use the below directly there will no issue even use the resizer.
The full error log can be found at the bottom.
# est = depth_est[mask]
# gt = depth_gt[mask]
def depth_norm(depth_tensor_np):
depth_min = torch.min(depth_tensor_np)
depth_max = torch.max(depth_tensor_np)
bits = 2
max_val = (2**(8*bits))-1
if depth_max - depth_min > torch.finfo(torch.float32).eps:
depth_map = max_val * (depth_tensor_np - depth_min) / (depth_max - depth_min)
else:
depth_map = 0
print('depth_min == depth_max = 0', depth_min, depth_max)
return depth_map
class silog_loss(nn.Module):
def __init__(self, variance_focus):
super(silog_loss, self).__init__()
self.variance_focus = variance_focus
def forward(self, depth_est, depth_gt, mask):
est = depth_norm(depth_est[mask])
gt = depth_norm(depth_gt[mask])
# est = depth_est[mask]
# gt = depth_gt[mask]
d = est - gt
return torch.sqrt((d ** 2).mean() - self.variance_focus * (d.mean() ** 2)) * 10.0
depth_min == depth_max = 0 tensor(0., device='cuda:0', grad_fn=<MinBackward1>) tensor(0., device='cuda:0', grad_fn=<MaxBackward1>)
Traceback (most recent call last):
File "bts_main.py", line 714, in <module>
main()
File "bts_main.py", line 709, in main
main_worker(0, ngpus_per_node, args)
File "bts_main.py", line 557, in main_worker
loss.backward()
File "/home/bigtree/miniconda3/envs/bigtree/lib/python3.7/site-packages/torch/tensor.py", line 245, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
File "/home/bigtree/miniconda3/envs/bigtree/lib/python3.7/site-packages/torch/autograd/__init__.py", line 147, in backward
allow_unreachable=True, accumulate_grad=True) # allow_unreachable flag
RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
It’s a bit hard to debug, as I’m unsure where these methods are used, so let me summarize what would be expected:
- your inputs do not require gradients (i.e. you are not updating the inputs in any way, which would be used in e.g. adversarial training)
- the resize method with numpy ops is used on the inputs before feeding them into the model
- the inputs are fed into the model, which only uses differentiable PyTorch ops
If all these points are true, then the error should not be raised.
Based on the error message I also don’t understand this output:
depth_min == depth_max = 0 tensor(0., device='cuda:0', grad_fn=<MinBackward1>) tensor(0., device='cuda:0', grad_fn=<MaxBackward1>)
which might be related to creating the issue.
In any case, since you cannot post the code, you could add debug print statements to the code and check all intermediate tensors for the .grad_fn op. If this would return a None value, it would mean that this tensor does not have a valid grad_fn and is thus detached.
1 Like
please
mse_loss:::: tensor(556009.5000, device=‘cuda:0’) after using ‘detach’ in line code
mse_loss = criterion_mse(fake_img.detach(), real_img) , it not has a valid grad_fn
instead of tensor(556009.5000, device=‘cuda:0’, grad_fn=)
Is that affect updates of models badly? or what is the grad_fn effect ?
The calculated mse_loss will also be detadched, so no gradients will be calculated for the model which created fake_img and I don’t know why you want to detach this tensor in this operation.
1 Like
to avoid this error
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [20, 1, 6, 32, 32]], which is output 0 of ReluBackward0, is at version 1; expected version 0 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True).
have you solution for this error without using detach ?please.
regards.
Anoud,
Detaching tensors doesn’t fix this issue, but would cut the computation graph so that Autograd never reaches the inplace operation causing the error.
To fix the inplace error: remove all inplace operations and replace them with their out-of-place equivalents.
sorry , I could not understand what do you mean, Just I need MseLoss values to update the loss of the generator not to update MseLoss .
g_loss = self.lambda_mse * mse_loss+dversarial_loss
g_loss.backward()
Based on your description, g_loss.backward() should calculate the gradients of the parameters of the generator. This would be the case, if mse_loss, adversarial_loss, or both were calculated using the output of the generator. However, if you detach the loss (which was created with the output of the generator), you will cut the computation graph and no gradients will be created.
Here is a small example:
generator = nn.Linear(1, 1)
output = generator(torch.randn(1, 1))
loss = F.mse_loss(output, torch.rand_like(output))
loss.backward()
# check gradients
for param in generator.parameters():
print(param.grad)
# now with detach
generator = nn.Linear(1, 1)
output = generator(torch.randn(1, 1))
loss = F.mse_loss(output.detach(), torch.rand_like(output))
loss.backward() # no gradient calculation possible, since output is detached
> RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
1 Like
yes, I used as exact code , both mse_loss, adversarial_loss were calculated using the output of the generator and the weights of the generator have gradients , and also they are updating for, along learning , I asked for ‘detach’ why it does not raise the error ? , I have not another solution instead of ‘detach’ to solve the first error.
Thanks, a lot
this dose not give me error , model is updating, but most suggestion avoids use detach?
fake_img = self.generator(z)
mse_loss = criterion_mse(fake_img.detach(), real_img)
g_loss = self.lambda_mse * mse_loss+dversarial_loss
g_loss.backward()
Your code snippet still detaches the generator output and thus no gradients coming from mse_loss will be created.
You are not seeing an error, since dversarial_loss also seems to be calculated with the outputs of generator. In this case, the gradients will only be calculated from dversarial_loss and mse_loss would act as a constant value.
1 Like
thanks, a lot
how can I solve this error instead of ‘detach’
::
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [20, 1, 6, 32, 32]], which is output 0 of ReluBackward0, is at version 1; expected version 0 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True)
how can I remove all inplace operations and replace them with their out-of-place equivalents.?
please, need a help
As previously described:
To fix the inplace error: remove all inplace operations and replace them with their out-of-place equivalents.
1 Like
i am so grateful to you, thanks
please, more details about this , how can I do this?
i don’t know how can I do this in code
regards,
Anoud
The quoted code snippet is used to verify that my first approach works correctly and you won’t be able to directly apply it, since your backward operation fails.
Check your code for inplace operations, such as:
a += 1
x.add_(b)
z[index] = c
and replace them with their out-of-place versions:
a = a + 1
x = x + b
1 Like
model_conv = torchvision.models.vgg16(pretrained=True)
for param in model_conv.parameters():
param.requires_grad = False
model_conv.classifier.requires_grad_=True
model_conv.classifier[6].out_features=len(class_names)
model_conv = model_conv.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that only parameters of final layer are being optimized as
# opposed to before.
optimizer_conv = optim.SGD(model_conv.classifier.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_conv, step_size=7, gamma=0.1)
Here in VGG16 model, I want to train the classifier layer on my images and freeze the conv layers. I am getting the same error
RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn