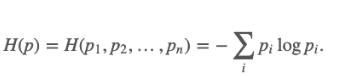Hi
i made a loss based on minus of the entropy of the softmax layer, such that the information will disperse well.
it all worked well, until somehow, something got wrong, and instead of making the information more dispersed,the data becomes more unique and from an array of random value, i get an array with all zeros except one element.
if i decrease the learning rate, the network converges, but less well than before.
That is expected behavior if you are minimizing the following objective:
H minimize (and it is equal to zero) if all p_i except one are zero.
so the last remaining p_i should be equal to 1.
hi
as i said, im trying to minimize the minus of the entropy (in order to maximze the entropy). so the information should not concentrate on one neoron, but it should disperse uniformly
import torch
data = torch.randn(100,2,requires_grad=True)
data.shape # >
optim = torch.optim.SGD([data], 0.1)
def loss(eta):
return torch.sum(eta*torch.log(eta))
for i in range(1000):
optim.zero_grad()
eta = torch.nn.functional.softmax(data,-1)
l = loss(eta)
l.backward()
optim.step()
if i%10 == 0:
print(i,l.item())
i see no problem.
it converges to all eta equal to 0.5.