Hi everyone, this is my first post here so don’t be too mean please.
I am struggling with a weird problem that consumes the double cuda memory of what I expected.
Here is a quick snippet to replicate the problem:
from torchvision.models import resnet50
import torch
# This loss consumes a lot of memory
class ZeroLoss(torch.nn.Module):
def forward(self, embeddings):
return torch.tensor([0.], requires_grad=True)
# This doesn't
class MeanLoss(torch.nn.Module):
def forward(self, embeddings):
return embeddings.mean() * 0.0
use_zeroloss = True
device = "cuda:0" if torch.cuda.is_available() else "cpu"
model = resnet50().to(device)
x = torch.randn(128, 3, 224, 224).to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=1e-5, momentum=0)
# MeanLoss use 15GB of Vram ZeroLoss use 24GB of Vram
criterion = ZeroLoss() if use_zeroloss else MeanLoss()
while True:
embeddings = model(x)
loss = criterion(embeddings)
loss.backward()
optimizer.step()
optimizer.zero_grad()
This is the minimum amount of code to replicate my problem.
Cuda memory used in above script with use_zeroloss = False (up) and use_zeroloss = True (down)
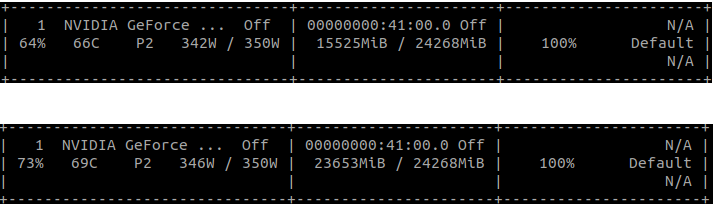
I expected ZeroLoss to save more memory than MeanLoss, but it’s actually the opposite and the gap is huge. Why?!?!?