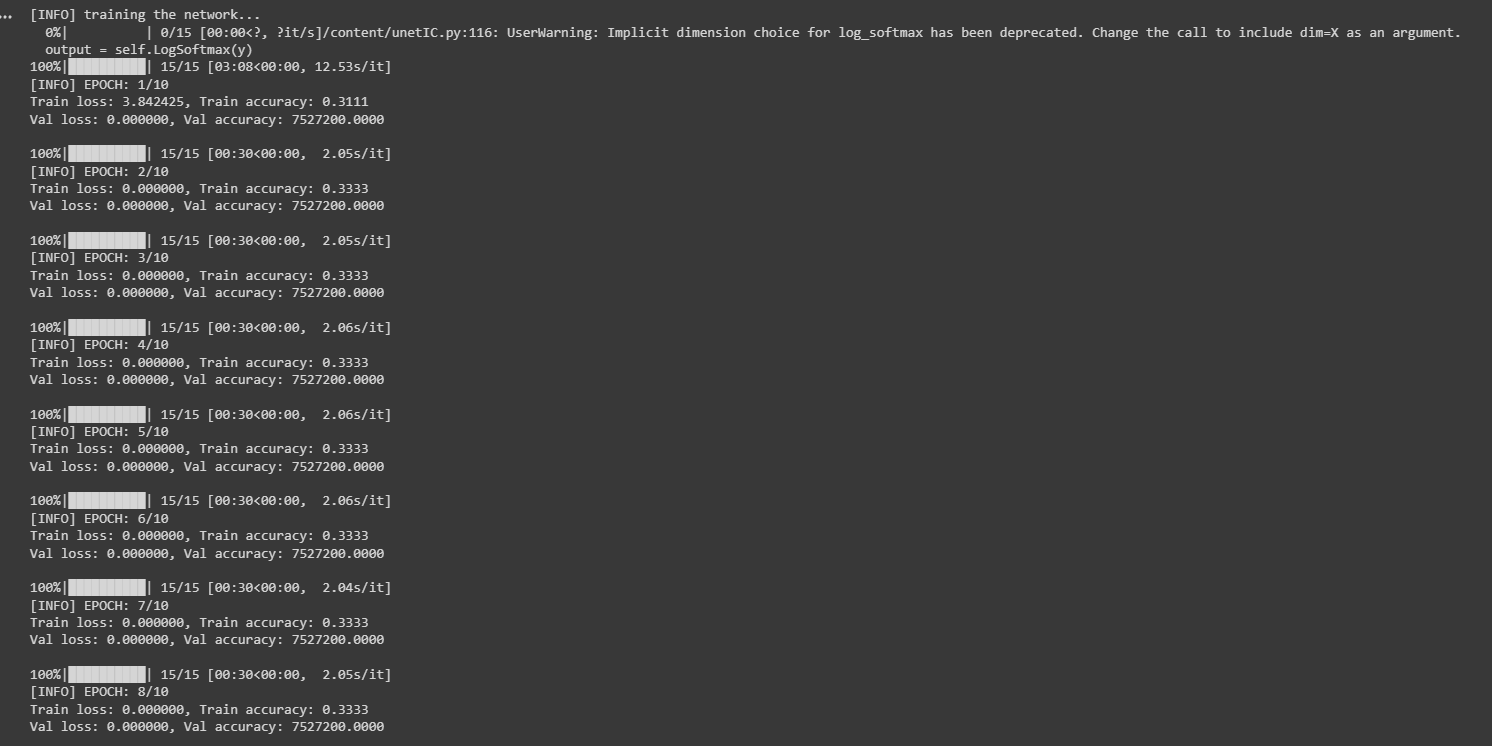
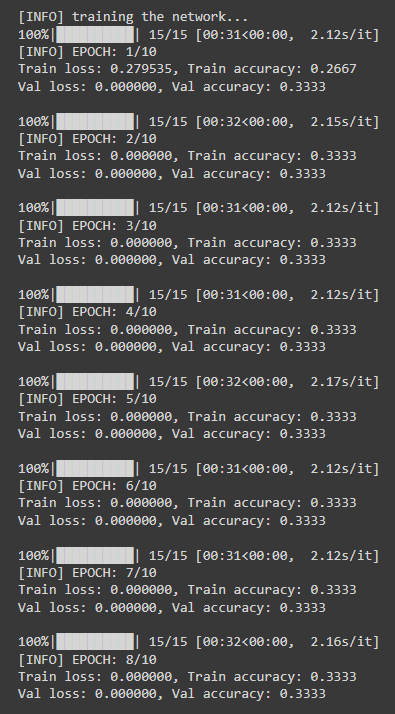
Hi there! I’m trying to code a CNN for image segmentation using a Raabin Dataset (Eosinophil)
My problem is: it’s training too fast (I didn’t expected that) and the values of loss and accuracy of each epochs are extremely high and I don’t know why.
My dataset looks like this:
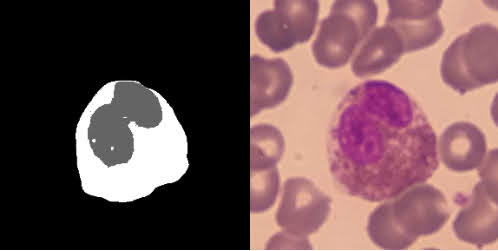
I’m using the UNet Architecture, the input image is 572x572 and the output image is 388x388.
Here is my dataset class:
class MyDataset(Dataset):
def __init__(self, root_dir, transform = None, transform2 = None):
self.root_dir = root_dir
self.names = os.listdir(os.path.join(self.root_dir, "Original"))
self.transform = transform
self.transform2 = transform2
def __len__(self):
return len(self.names)
def classes(self):
return torch.Tensor([0,1,2])
def __getitem__(self, idx):
if torch.is_tensor(idx):
idx = idx.tolist()
image_name = self.names[idx]
image = io.imread(os.path.join(self.root_dir, "Original", image_name))
label = io.imread(os.path.join(self.root_dir, "Ground Truth", image_name))
if self.transform is not None:
image = self.transform(image)
if self.transform2 is not None:
label = self.transform2(label)
return image, label
transformations = transforms.Compose(
[transforms.ToTensor(),
transforms.CenterCrop(572)]
)
transformations2 = transforms.Compose(
[transforms.ToTensor(),
transforms.CenterCrop(388)]
)
Here is my pre-training and validating settings:
learning_rate = 1e-3
batch_size = 10
epochs = 10
train_split = 0.75
val_split = 1 - train_split
train_data = MyDataset(root_dir = root, transform = transformations, transform2 = transformations2)
val_data = MyDataset(root_dir = root, transform = transformations, transform2 = transformations2)
test_data = MyDataset(root_dir = root, transform = transformations, transform2 = transformations2)
f = len(train_data)
#trainig and validation splits
numTrainSamples = int(len(train_data) * train_split)
numValSamples = int(len(train_data) * val_split)
(train_data, val_data) = random_split(train_data, [numTrainSamples, numValSamples], generator=torch.Generator().manual_seed(42))
#dataloaders for training, test and validation
train_dataLoader = DataLoader(train_data, batch_size = batch_size, shuffle = True)
test_dataLoader = DataLoader(test_data, batch_size = batch_size)
val_dataLoader = DataLoader(val_data, batch_size = batch_size )
#steps per epoch
train_Steps = len(train_dataLoader.dataset) // batch_size
val_Steps = len(val_dataLoader.dataset) // batch_size
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = unetIC.Unet().to(device)
opt = Adam(model.parameters(), lr = learning_rate)
lossFn = nn.NLLLoss()
H = {
"train_loss": [],
"train_acc": [],
"val_loss": [],
"val_acc": []
}
Here is my training function:
def training(model, dataloader, lossFn, opt):
model.train()
totalTrainLoss = 0
trainCorrect = 0
for x, y in dataloader:
x = x.to(device)
y = torch.argmax(y, dim=1).to(device)
pred = model(x)
loss = lossFn(pred, y)
opt.zero_grad()
loss.backward()
opt.step()
totalTrainLoss += loss
trainCorrect += (pred.argmax(1) == y).type(torch.float).sum().item()
return totalTrainLoss, trainCorrect
And my validation function:
def validation(model, dataloader, lossFn):
with torch.no_grad():
totalValLoss = 0
valCorrect = 0
model.eval()
for x, y in dataloader:
x = x.to(device)
y = torch.argmax(y, dim=1).to(device)
pred = model(x)
loss = lossFn(pred, y)
totalValLoss += lossFn(pred, y)
valCorrect += (pred.argmax(1) == y).type(torch.float).sum().item()
return totalValLoss, valCorrect
I call the functions in this for loop running from 0 to the number of epochs:
for e in range(0, epochs):
#calling the training and validation functions
(totalTrainLoss, trainCorrect) = treino(model, train_dataLoader, lossFn, opt)
(totalValLoss, valCorrect) = validacao(model, train_dataLoader, lossFn)
avgTrainLoss = totalTrainLoss / train_Steps
avgValLoss = totalValLoss / val_Steps
trainCorrect = trainCorrect / len(train_dataLoader.dataset)
valCorrect = valCorrect / len(val_dataLoader.dataset)
H["train_loss"].append(avgTrainLoss.cpu().detach().numpy())
H["train_acc"].append(trainCorrect)
H["val_loss"].append(avgValLoss.cpu().detach().numpy())
H["val_acc"].append(valCorrect)
print("[INFO] EPOCH: {}/{}".format(e + 1, epochs))
print("Train loss: {:.6f}, Train accuracy: {:.4f}".format(avgTrainLoss, trainCorrect))
print("Val loss: {:.6f}, Val accuracy: {:.4f}\n".format(avgValLoss, valCorrect))
And my output is:
[INFO] EPOCH: 1/10
Train loss: -73854244356096.000000, Train accuracy: 150544.0000
Val loss: -14140576379174912.000000, Val accuracy: 451632.0000
[INFO] EPOCH: 2/10
Train loss: -8068695254293161181184.000000, Train accuracy: 150544.0000
Val loss: -286677823230570548690944.000000, Val accuracy: 451632.0000
[INFO] EPOCH: 3/10
Train loss: -474880297297028021485568.000000, Train accuracy: 150544.0000
Val loss: -2437206597218221944733696.000000, Val accuracy: 451632.0000
[INFO] EPOCH: 4/10
Train loss: -1053400599753243565752320.000000, Train accuracy: 150544.0000
Val loss: -3972704350541768166473728.000000, Val accuracy: 451632.0000
[INFO] EPOCH: 5/10
Train loss: -1551795019367104383025152.000000, Train accuracy: 150544.0000
Val loss: -5417466316761627076067328.000000, Val accuracy: 451632.0000
[INFO] EPOCH: 6/10
Train loss: -2018213305165882375274496.000000, Train accuracy: 150544.0000
Val loss: -6768582522000170991747072.000000, Val accuracy: 451632.0000
[INFO] EPOCH: 7/10
Train loss: -2457880497408455772995584.000000, Train accuracy: 150544.0000
Val loss: -8055248685748935251197952.000000, Val accuracy: 451632.0000
[INFO] EPOCH: 8/10
Train loss: -2879512538554464263471104.000000, Train accuracy: 150544.0000
Val loss: -9298824984723770908344320.000000, Val accuracy: 451632.0000
[INFO] EPOCH: 9/10
Train loss: -3289052738960156142862336.000000, Train accuracy: 150544.0000
Val loss: -10510818728462158902853632.000000, Val accuracy: 451632.0000
[INFO] EPOCH: 10/10
Train loss: -3689216805229632839221248.000000, Train accuracy: 150544.0000
Val loss: -11701086819367735472947200.000000, Val accuracy: 451632.0000
[INFO] total time taken to train the model: 633.10s
The values of train and validation loss are super weird, and so are their accuracy as well. And it’s running 10 epochs in just 10 minutes. I need some guidance!
Any help would be deeply appreciated! ![]()
Thanks in advance!