Following my previous question, (Fastfood random projection), I am implementing Fast Walsh-Hadamard transform (FWHT) in Pytorch extending autograd Function, in order to be able to propagate gradients through it. This is done very easily: as the Walsh-Hadamard transform is equal to its inverse, the same transformation is applied in the forward and backward pass.
The point is that I found a big time difference when computing the transformation itself operating on Pytorch tensors or on Numpy array (20x slower with tensors). Specifically, the following piece of code operates on tensor:
class FWHT_OLD(Function):
def transform(tensor):
""" Simple implementation of FWHT, receiving as input a torch Tensor. """
bit = length = len(tensor)
result = torch.tensor(tensor)
for _ in range(int(np.log2(length))):
bit >>= 1
for i in range(length): # d loops
if i & bit == 0:
j = i | bit
temp = torch.tensor(result[i]) # otherwise it copies by reference!
result[i] += result[j]
result[j] = temp - result[j]
result /= np.sqrt(length) # normalize
return result
@staticmethod
def forward(ctx, input):
return FWHT_OLD.transform(input)
@staticmethod
def backward(ctx, grad_output):
return FWHT_OLD.transform(grad_output)
While the following does the same operation but converting the tensor to a numpy array (only the lines with a comment changed with respect to previous one):
class FWHT(Function):
def transform(tensor):
""" Simple implementation of FWHT, receiving as input a torch Tensor. """
bit = length = len(tensor)
result = tensor.detach().numpy() # transform to numpy
for _ in range(int(np.log2(length))):
bit >>= 1
for i in range(length):
if i & bit == 0:
j = i | bit
temp = result[i] # this copies by value
result[i] += result[j]
result[j] = temp - result[j]
result /= np.sqrt(length)
return torch.from_numpy(result) # transform back to torch
@staticmethod
def forward(ctx, input):
return FWHT.transform(input)
@staticmethod
def backward(ctx, grad_output):
return FWHT.transform(grad_output)
In the following picture there is a time analysis of the performance of the algorithm in forward and backward pass. The yellow line is the comparison with a pure numpy code.
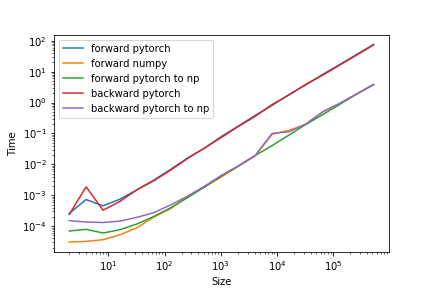
Does anybody have a clue on why this happens?
DISCLAIMER: My code was inspired from https://gist.github.com/dougalsutherland/1a3c70e57dd1f64010ab