I have Gigapixel images that I have divided into 512x512 patches and have fed each patch into a ResNet18 using img2vec library to get a 512 1D tensor. So let’s call a 500 patch image of size 500x512 an intermediate representation.
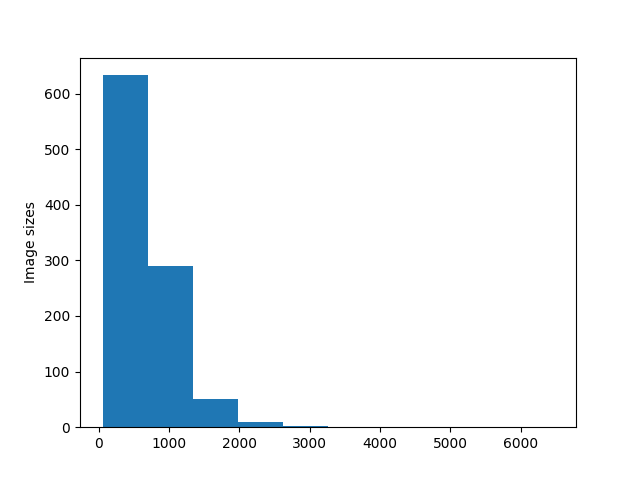
My images size in terms of a number of patches inside them ranges from 51 to 6500 with a mean of 670 patches inside one image.
When I want to feed them into a vanilla vision transformer, I am required to stack these intermediate representation within a patch however torch.stack requires to have the first dimension same so I can’t have intermediate representations of different sizes.
Initially, I did zero-filling inside each batch such that I zero-filled rest of the intermediate representation in a batch to become the size of the largest intermediate representation in a batch. However, this method didn’t yield good results.
The other method I tried, is sampling 50 patches in each original image. This method unfortunately isn’t having a good performance as well.
So, my question is, what is the best way for feeding images in one batch (e.g. batch size of 64) in which the images or intermediate representations are not of the same size and differ a lot in their sizes?
Here’s the list of number of patches in each image:
[51, 69, 74, 74, 80, 84, 89, 91, 93, 121, 122, 123, 126, 127, 134, 135, 146, 147, 148, 152, 157, 159, 159, 162, 162, 165, 171, 175, 175, 177, 181, 182, 185, 186, 186, 188, 189, 192, 193, 194, 194, 198, 198, 199, 201, 201, 202, 203, 203, 204, 206, 209, 209, 209, 210, 211, 211, 212, 214, 217, 220, 223, 224, 225, 227, 228, 228, 228, 230, 231, 233, 233, 233, 234, 236, 236, 237, 238, 238, 238, 239, 241, 242, 243, 243, 244, 245, 246, 247, 248, 249, 249, 253, 253, 253, 255, 256, 258, 258, 258, 264, 267, 268, 271, 272, 273, 275, 277, 278, 279, 280, 281, 287, 287, 287, 289, 289, 290, 291, 292, 293, 293, 297, 298, 298, 298, 298, 299, 300, 300, 301, 301, 301, 302, 304, 305, 306, 308, 308, 309, 316, 316, 317, 319, 320, 320, 320, 321, 321, 322, 323, 324, 325, 325, 325, 331, 331, 332, 332, 332, 332, 334, 335, 336, 337, 338, 338, 339, 340, 341, 341, 342, 345, 345, 345, 346, 346, 347, 347, 348, 349, 350, 352, 352, 354, 355, 355, 356, 356, 357, 357, 358, 359, 361, 361, 362, 362, 363, 363, 366, 366, 367, 367, 368, 368, 369, 369, 370, 370, 371, 372, 372, 373, 376, 377, 379, 379, 381, 383, 383, 383, 384, 385, 385, 387, 387, 390, 390, 392, 393, 394, 395, 396, 396, 397, 397, 397, 399, 399, 400, 400, 400, 400, 402, 402, 405, 406, 407, 408, 410, 410, 411, 411, 411, 412, 414, 414, 414, 414, 416, 417, 417, 417, 418, 419, 419, 419, 421, 421, 422, 423, 423, 424, 424, 424, 425, 425, 425, 426, 426, 427, 427, 427, 427, 427, 429, 429, 429, 430, 430, 431, 432, 433, 433, 433, 434, 434, 435, 435, 435, 436, 437, 437, 437, 439, 442, 442, 442, 443, 443, 443, 444, 444, 444, 446, 446, 446, 447, 447, 448, 448, 449, 449, 449, 453, 453, 453, 453, 454, 455, 456, 456, 456, 456, 458, 458, 459, 459, 459, 460, 460, 462, 463, 463, 463, 465, 466, 466, 466, 467, 467, 469, 469, 470, 470, 471, 472, 472, 472, 473, 473, 473, 475, 476, 476, 476, 477, 477, 478, 478, 479, 479, 479, 481, 481, 481, 482, 482, 482, 483, 484, 484, 486, 486, 486, 486, 487, 487, 487, 488, 490, 490, 490, 491, 492, 492, 493, 493, 493, 494, 495, 496, 496, 496, 496, 497, 497, 498, 499, 500, 501, 504, 504, 505, 505, 506, 507, 508, 509, 510, 510, 511, 512, 513, 513, 514, 514, 515, 516, 520, 523, 524, 525, 525, 525, 526, 526, 527, 527, 528, 531, 531, 533, 534, 534, 534, 537, 537, 540, 542, 544, 546, 546, 548, 548, 549, 551, 551, 551, 552, 553, 555, 555, 557, 558, 558, 558, 559, 559, 560, 560, 561, 561, 563, 563, 565, 565, 565, 570, 572, 574, 574, 575, 576, 576, 576, 576, 577, 578, 580, 580, 581, 581, 581, 581, 582, 582, 585, 585, 585, 585, 586, 586, 587, 587, 588, 588, 589, 590, 591, 592, 592, 594, 594, 595, 595, 595, 596, 597, 598, 598, 598, 599, 600, 601, 601, 602, 603, 603, 604, 606, 606, 606, 608, 609, 609, 611, 613, 613, 613, 614, 615, 616, 616, 616, 617, 617, 617, 618, 619, 620, 621, 621, 622, 623, 623, 624, 625, 625, 625, 626, 628, 628, 629, 630, 631, 632, 632, 634, 634, 634, 635, 636, 637, 638, 638, 639, 640, 642, 642, 643, 646, 646, 646, 649, 650, 651, 652, 652, 654, 654, 654, 655, 656, 656, 657, 658, 658, 659, 659, 660, 660, 665, 665, 666, 667, 668, 668, 669, 672, 672, 673, 673, 676, 676, 676, 677, 677, 677, 679, 680, 681, 681, 682, 682, 683, 684, 685, 685, 686, 686, 688, 690, 694, 694, 694, 696, 696, 697, 697, 698, 699, 700, 700, 700, 702, 702, 705, 706, 708, 709, 711, 713, 713, 717, 718, 719, 720, 721, 721, 721, 721, 722, 722, 723, 725, 727, 727, 729, 729, 733, 734, 735, 735, 742, 742, 743, 744, 745, 746, 749, 752, 752, 754, 754, 758, 759, 761, 762, 763, 763, 764, 765, 766, 767, 767, 771, 772, 776, 777, 777, 778, 780, 782, 783, 785, 785, 785, 786, 786, 787, 787, 789, 790, 791, 793, 795, 795, 796, 796, 797, 797, 797, 797, 799, 800, 802, 803, 803, 803, 803, 803, 806, 812, 813, 815, 816, 818, 818, 821, 824, 830, 832, 832, 833, 834, 834, 835, 836, 836, 837, 838, 838, 842, 843, 844, 845, 845, 847, 847, 848, 851, 852, 855, 855, 856, 858, 864, 865, 866, 871, 871, 871, 874, 876, 877, 878, 887, 888, 888, 890, 890, 891, 895, 897, 898, 900, 901, 903, 905, 906, 906, 907, 911, 917, 917, 920, 923, 923, 924, 930, 930, 930, 932, 936, 938, 939, 945, 945, 950, 950, 952, 955, 957, 958, 959, 959, 959, 959, 962, 962, 965, 968, 969, 971, 972, 972, 978, 978, 981, 983, 984, 986, 990, 991, 992, 998, 999, 999, 1002, 1004, 1006, 1011, 1014, 1018, 1023, 1025, 1029, 1033, 1035, 1041, 1044, 1044, 1047, 1049, 1052, 1052, 1054, 1059, 1060, 1063, 1065, 1069, 1069, 1072, 1078, 1082, 1083, 1085, 1085, 1090, 1096, 1097, 1099, 1099, 1100, 1108, 1111, 1114, 1115, 1122, 1138, 1139, 1143, 1149, 1151, 1152, 1154, 1156, 1158, 1159, 1161, 1164, 1179, 1183, 1190, 1198, 1199, 1200, 1206, 1212, 1213, 1218, 1220, 1229, 1229, 1237, 1245, 1262, 1262, 1278, 1281, 1292, 1298, 1298, 1299, 1303, 1306, 1309, 1309, 1324, 1329, 1330, 1350, 1363, 1370, 1375, 1412, 1424, 1431, 1432, 1436, 1460, 1476, 1476, 1489, 1497, 1499, 1512, 1514, 1520, 1526, 1529, 1550, 1554, 1558, 1570, 1577, 1582, 1599, 1613, 1625, 1636, 1646, 1665, 1670, 1686, 1758, 1760, 1784, 1786, 1797, 1823, 1825, 1828, 1846, 1848, 1851, 1863, 1868, 1887, 1925, 1950, 1979, 2009, 2028, 2077, 2099, 2132, 2147, 2158, 2211, 2269, 2807, 2971, 3559, 6469]
Here’s the code for vanilla transformer (please note I am doing regression vs the original classification):
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class PositionEmbs(nn.Module):
def __init__(self, num_patches, emb_dim, dropout_rate=0.1):
super(PositionEmbs, self).__init__()
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, emb_dim))
if dropout_rate > 0:
self.dropout = nn.Dropout(dropout_rate)
else:
self.dropout = None
def forward(self, x):
out = x + self.pos_embedding
if self.dropout:
out = self.dropout(out)
return out
class MlpBlock(nn.Module):
""" Transformer Feed-Forward Block """
def __init__(self, in_dim, mlp_dim, out_dim, dropout_rate=0.1):
super(MlpBlock, self).__init__()
# init layers
self.fc1 = nn.Linear(in_dim, mlp_dim)
self.fc2 = nn.Linear(mlp_dim, out_dim)
self.act = nn.GELU()
if dropout_rate > 0.0:
self.dropout1 = nn.Dropout(dropout_rate)
self.dropout2 = nn.Dropout(dropout_rate)
else:
self.dropout1 = None
self.dropout2 = None
def forward(self, x):
out = self.fc1(x)
out = self.act(out)
if self.dropout1:
out = self.dropout1(out)
out = self.fc2(out)
out = self.dropout2(out)
return out
class LinearGeneral(nn.Module):
def __init__(self, in_dim=(768,), feat_dim=(12, 64)):
super(LinearGeneral, self).__init__()
self.weight = nn.Parameter(torch.randn(*in_dim, *feat_dim))
self.bias = nn.Parameter(torch.zeros(*feat_dim))
def forward(self, x, dims):
a = torch.tensordot(x, self.weight, dims=dims) + self.bias
return a
class SelfAttention(nn.Module):
def __init__(self, in_dim, heads=8, dropout_rate=0.1):
super(SelfAttention, self).__init__()
self.heads = heads
self.head_dim = in_dim // heads
self.scale = self.head_dim ** 0.5
self.query = LinearGeneral((in_dim,), (self.heads, self.head_dim))
self.key = LinearGeneral((in_dim,), (self.heads, self.head_dim))
self.value = LinearGeneral((in_dim,), (self.heads, self.head_dim))
self.out = LinearGeneral((self.heads, self.head_dim), (in_dim,))
if dropout_rate > 0:
self.dropout = nn.Dropout(dropout_rate)
else:
self.dropout = None
def forward(self, x):
b, n, _ = x.shape
q = self.query(x, dims=([2], [0]))
k = self.key(x, dims=([2], [0]))
v = self.value(x, dims=([2], [0]))
q = q.permute(0, 2, 1, 3)
k = k.permute(0, 2, 1, 3)
v = v.permute(0, 2, 1, 3)
attn_weights = torch.matmul(q, k.transpose(-2, -1)) / self.scale
attn_weights = F.softmax(attn_weights, dim=-1)
out = torch.matmul(attn_weights, v)
out = out.permute(0, 2, 1, 3)
out = self.out(out, dims=([2, 3], [0, 1]))
return out
class EncoderBlock(nn.Module):
def __init__(self, in_dim, mlp_dim, num_heads, dropout_rate=0.1, attn_dropout_rate=0.1):
super(EncoderBlock, self).__init__()
self.norm1 = nn.LayerNorm(in_dim)
self.attn = SelfAttention(in_dim, heads=num_heads, dropout_rate=attn_dropout_rate)
if dropout_rate > 0:
self.dropout = nn.Dropout(dropout_rate)
else:
self.dropout = None
self.norm2 = nn.LayerNorm(in_dim)
self.mlp = MlpBlock(in_dim, mlp_dim, in_dim, dropout_rate)
def forward(self, x):
residual = x
out = self.norm1(x)
out = self.attn(out)
if self.dropout:
out = self.dropout(out)
out += residual
residual = out
out = self.norm2(out)
out = self.mlp(out)
out += residual
return out
class Encoder(nn.Module):
def __init__(self, num_patches, emb_dim, mlp_dim, num_layers=12, num_heads=12, dropout_rate=0.1, attn_dropout_rate=0.0):
super(Encoder, self).__init__()
# positional embedding
self.pos_embedding = PositionEmbs(num_patches, emb_dim, dropout_rate)
# encoder blocks
in_dim = emb_dim
self.encoder_layers = nn.ModuleList()
for i in range(num_layers):
layer = EncoderBlock(in_dim, mlp_dim, num_heads, dropout_rate, attn_dropout_rate)
self.encoder_layers.append(layer)
self.norm = nn.LayerNorm(in_dim)
def forward(self, x):
#out = self.pos_embedding(x) # mona, is it ok to get rid of position embedding in this case?
out = x
for layer in self.encoder_layers:
out = layer(out)
out = self.norm(out)
return out
class VisionTransformer(nn.Module):
""" Vision Transformer """
def __init__(self,
image_size=(256, 256),
patch_size=(16, 16),
emb_dim=512,
mlp_dim=3072,
num_heads=12,
num_layers=12,
attn_dropout_rate=0.0,
dropout_rate=0.1,
feat_dim=None):
super(VisionTransformer, self).__init__()
h, w = image_size
# embedding layer
fh, fw = patch_size
gh, gw = h // fh, w // fw
num_patches = gh * gw
self.embedding = nn.Conv2d(3, emb_dim, kernel_size=(fh, fw), stride=(fh, fw))
# class token
self.cls_token = nn.Parameter(torch.zeros(1, 1, emb_dim))
# transformer
self.transformer = Encoder(
num_patches=num_patches,
emb_dim=emb_dim,
mlp_dim=mlp_dim,
num_layers=num_layers,
num_heads=num_heads,
dropout_rate=dropout_rate,
attn_dropout_rate=attn_dropout_rate)
# classfier
###self.classifier = nn.Linear(emb_dim, num_classes)
## regressor
self.mlp_head = nn.Sequential(
nn.LayerNorm(emb_dim),
nn.Linear(emb_dim, 1) #mona does this make sense for regression using transformer?
)
def forward(self, x):
# Use feature extractor to get embedding for each patch
# emb = self.embedding(x) # (n, c, gh, gw)
# emb = emb.permute(0, 2, 3, 1) # (n, gh, hw, c)
# b, h, w, c = emb.shape
# emb = emb.reshape(b, h * w, c)
# prepend class token
B, _, _ = x.shape
cls_token = self.cls_token.repeat(B, 1, 1)
emb = torch.cat([cls_token, x], dim=1)
# transformer
feat = self.transformer(emb)
# regression
return self.mlp_head(feat[:, 0]) # is this correct
if __name__ == '__main__':
model = VisionTransformer(num_layers=4)
x = torch.randn((2, 3, 256, 256)) ## why are we doing this? #mona
out = model(x)
state_dict = model.state_dict()
for key, value in state_dict.items():
print("{}: {}".format(key, value.shape))
And here’s where I am using torch.stack to pass the intermediate representations to the ViT.py:
import sys
import os
import torch
import random
import numpy as np
import pdb
from torch.autograd import Variable
from torch.nn.parameter import Parameter
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from .ViT import VisionTransformer # for using vanilla transformer
class RMSELoss(nn.Module):
def __init__(self, eps=1e-6):
super().__init__()
self.mse = nn.MSELoss()
self.eps = eps
def forward(self,yhat,y):
loss = torch.sqrt(self.mse(yhat,y) + self.eps) #eps added to avoid NANs if mse=0
return loss
class Regressor(nn.Module):
def __init__(self, batch_size):
super(Regressor, self).__init__()
self.batch_size = batch_size
self.transformer = VisionTransformer()
self.criterion = RMSELoss()
def forward(self, X, targets, is_print=False):
stacked_X = torch.stack(X)
float_targets = []
for target in targets:
float_targets.append(float(target))
targets = torch.FloatTensor(float_targets)
targets = targets.cuda()
out = self.transformer(stacked_X)
out = out.reshape(len(targets))
loss = self.criterion(out, targets.float())
pred = out
return pred, targets, loss
Please let me know what are some of the possible options for my case.
I am currently sampling 50 patches from each image intermediate representation in a helper function dataset.py as below:
if os.path.exists(feature_path):
features = torch.load(feature_path, map_location=lambda storage, loc: storage)
else:
print("OS PATH DID NOT EXIST!!!!!!!!!!!!!!!!!")
features = torch.zeros(256, 512)
## sample['image'] = features ## using the entire image
random_indices = torch.randint(features.shape[0], (50, )) # picking 50 random row/patch indices from the entire image
sample['image'] = features[random_indices, :] ## using 50 random patches from the entire image
##sample['image'] = transformed_features
return sample
Please note that I am creating the intermediate representation of these Gigapixel images offline and then only feed the 2D torch tensors of NxD (N number of patches, D: 512) to my deep learning framework.
P.S.: Here’s the distribution of images based on their number of patches: