Hello,
I am trying to train a semantic segmentation network for the first time and in general I am still quite new with PyTorch.
My inputs are RGB-images and corresponding grayscale images. In them the grayscale intensity corresponds to the pixel class.
Please see my first try in the following.
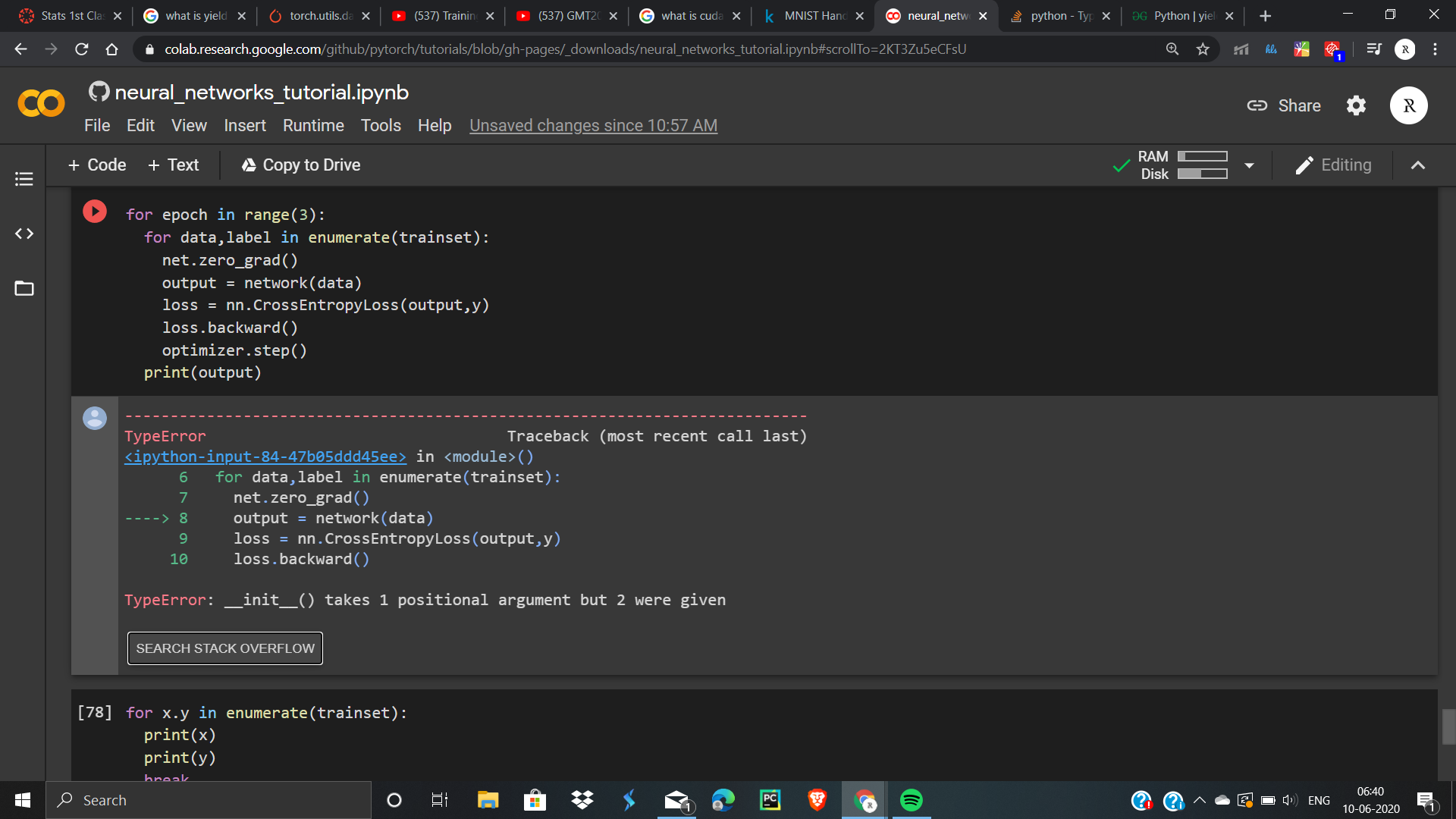
Right now I am getting the error: “Expected 4-dimensional input for 4-dimensional weight 64 3 7 7, but got 3-dimensional input of size [1, 1000, 1000] instead” from the line “output = model(img)” in the training loop.
The input with 1x1000x100 is the mask with the class labels.
How can this be solved and do you have further advises for me?
Thank you very much 
import torch
import os
import numpy as np
import torch.nn as nn
import torch.optim as optim
# DataLoader
from PIL import Image
from torchvision import transforms
from torch.utils.data.sampler import SubsetRandomSampler
class Dataset(torch.utils.data.Dataset):
def __init__(self, root, transforms=None):
self.root = root
self.transforms = transforms
# load all image files, sorting them to ensure that they are aligned
self.imgs = list(sorted(os.listdir(os.path.join(root, "Images")))) # Subfolder with images
self.masks = list(sorted(os.listdir(os.path.join(root, "ImageLabels")))) # Subfolder with masks
def __getitem__(self, idx):
# load images ad masks
img_path = os.path.join(self.root, "Images", self.imgs[idx])
mask_path = os.path.join(self.root, "ImageLabels", self.masks[idx])
img = Image.open(img_path).convert("RGB") # Three channel rgb images
mask = Image.open(mask_path) # Single channel and the pixelintensity corresponds to the class label
if self.transforms is not None:
img = self.transforms(img)
mask = self.transforms(mask)
img =transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])(img)
# No need to normalize masks, they are all equal
return img, mask
def __len__(self):
return len(self.imgs)
transformations = transforms.Compose([
transforms.CenterCrop(1000),
transforms.ToTensor()
])
# Load data
dataset = Dataset('/images/', transforms=transformations)
# Split data (Random)
train_size = int(0.8 * len(dataset))
test_size = len(dataset) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(dataset, [train_size, test_size])
dataloader_train=torch.utils.data.DataLoader(train_dataset,
batch_size=10, shuffle=True)
dataloader_test=torch.utils.data.DataLoader(test_dataset,
batch_size=10, shuffle=False)
# Model:
from torchvision import models
model = models.segmentation.deeplabv3_resnet101(pretrained=False, progress=True, num_classes=output_classes)
criterion = nn.BCEWithLogitsLoss().cuda
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
model.train()
# Use gpu if available
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
model = nn.DataParallel(model)
model.to(device)
# Training
num_epochs = 1
for iter in range(num_epochs):
# Training:
model.train()
for i in range(len(train_loader)):
img, mask = train_loader[i]
img, mask = img.cuda(), mask.cuda()
optimizer.zero_grad()
img = img.to(device)
mask = mask.to(device)
output = model(img)
loss = criterion(output, mask)
print(loss.cpu())
loss.backward()
optimizer.step()
# Validation:
model.eval()
for i in range(len(test_loader)):
img, mask = test_loader[i]
img, mask = img.cuda(), mask.cuda()
output = model.forward(img) # forward pass
loss = criterion(output, mask)
print(loss.cpu())