I trained a model, the performance during the training is here:
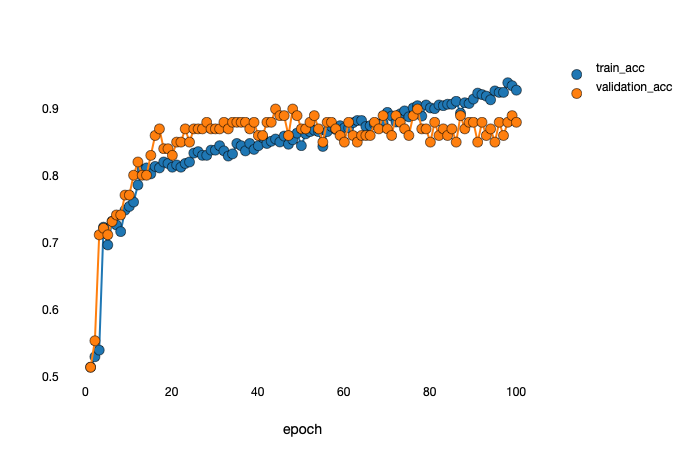
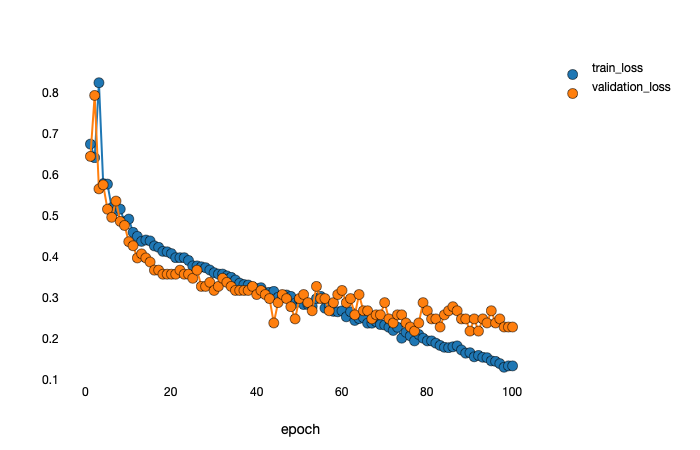
I thought the parameters of epoch 44, is the best one. Then I loaded the parameters of epoch 44:
model = Model()
model.to(device=args.device)
model.load_state_dict(torch.load(args.weight_path))
criterion_reduction_none = nn.CrossEntropyLoss(reduction='none')
model.eval()
After that, I tried to predict the same data set to observe the performance of the model.
Originally, I thought that the prediction result of the model would always be the value of epoch 44.
In my opinion, it’s just like getting the value of y = f(x).
The f is just like the frozen parameter model; the x is just like the data set here.
But in fact, the performance of the model is fluctuating within a certain range like:
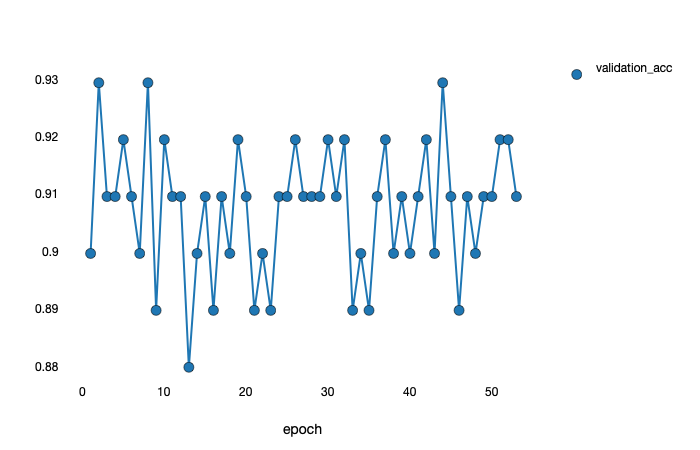
Why it came out like this?
Here is my model:
class Model(nn.Module):
def forward(self, input_image):
out = self.conv_1(input_image) # 20 * 44 * 44
out = self.pooling_1(out) # 20 * 22 * 22
out = self.conv_2(out) # 50 * 16 * 16
out = self.pooling_2(out) # 50 * 8 * 8
out = self.conv_3(out) # 500 * 2 * 2
out = self.pooling_3(out) # 500 * 1 * 1
out = F.dropout(out)
out = F.relu(out)
out = self.conv_4(out) # 2 * 1 * 1
I heard that model.eval() is needed when there is a dropout layer in the model. I actually did it.
Or is this the normal state of any deep learning model?