-
is there any way possible to do fusing on FC layers
-
Can we do do fusing of Bnorm , when Linear/Conv followed by BnormI.
Fusing? What do you mean?
Using 2 FC layers with no non-linearities in between is equivalent to using a single FC as they are linear.
here is the code ,i want to fuse the FC3 layer(last layer which is linear) with bnorm(nn.BatchNorm1d) is that possible?
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.num_classes = num_classes
self.features = nn.Sequential(
nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=0),
nn.BatchNorm2d(96, eps=1e-4, momentum=0.1, affine=True),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
BinConv2d(96, 256, kernel_size=5, stride=1, padding=2, groups=1),
nn.MaxPool2d(kernel_size=3, stride=2),
BinConv2d(256, 384, kernel_size=3, stride=1, padding=1),
BinConv2d(384, 384, kernel_size=3, stride=1, padding=1, groups=1),
BinConv2d(384, 256, kernel_size=3, stride=1, padding=1, groups=1),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.classifier = nn.Sequential(
BinConv2d(256 * 6 * 6, 4096, Linear=True),
BinConv2d(4096, 4096, dropout=0.5, Linear=True),
nn.BatchNorm1d(4096, eps=1e-3, momentum=0.1, affine=True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), 256 * 6 * 6)
x = self.classifier(x)
return x```Well, still don’t understand what do you mean by fuse but yes. You can use batchnorm after a linear layer if the output is a 2D tensor.
Think that Pytorch’s implementation of Linear allows to use N-Dimensional tensors.
I want to fuse bnorm weight with linear weight ,where linear follows the bnorm(bnorm comes first ,then linear next). is it possible?
can you provide the sequences possible for fusing?
Something like the following?
import torch
from torch import nn
class BNLinear:
def __init__(self, in_features: int, out_features: int, bias: bool = True):
self.linear = nn.Linear(in_features, out_features, bias)
self.batch_norm = nn.BatchNorm1d(in_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
def forward(self, x):
x = self.batch_norm(x)
return self.linear(x)
I have a Relu in between 2FC as non-linearities ,in that case can we fuse the linear wegihts with bnorm weights
Well not in principle. The weights itself are dedicated to learn different stuff. There are not even the same amount of parameters.
Are you talking about the 2FC layers?Can you be please more specific,I have struck in this for long time. your help in this are more appreciated
1.Basically i am replicating the software in hardware(verilog coding),so to code Bnorm in hardware its very complicated
2.So i have fused(learnable parametrs) the Bnorm of my first layer with Conv (Conv->Bnorm)
3. For FC I have Bnorm in 3rd FC layer, I want to avoid these in my model, so it will be useful to code in hardware
4. So thought of fusing Bnorm with near by layers
5.My FC2 and FC3 layers looks like (Linear->Relu->Bnorm->dropout->Linear)
6.I tried to fuse (Linear->Relu->Bnorm->dropout->Linear) it didn’t worked out due to its shape
7. So I tried to fuse (Linear->Relu->Bnorm->dropout->Linear), I fused it but prediction are not correct by taking fused weights and bias
8.So I want to try to fuse(learnable parameter) (Linear->Relu) and then fused result again to fuse with Bnorm
9.Is that possible to do ?
Your help will be appreciated
What you mean by fuse is very confusing and unclear.
For example:
Is very confusing, since the normal ReLU is a classical activation function defined as ReLU(x)=max(0,x) and has no learnable parameters (unlike activation functions like PReLU).
I think everything that can be said was already said by @JuanFMontesinos
If this is not the answer you are looking for
then this is probably your answer:
-
My main Intention is to fuse bnorm, (linear->relu->bnorm), but to fuse bnorm with linear,in between i have relu,so i thought to fuse linear and relu and then with bnorm
-
ok , I got it Relu doesn’t have learnable parameters,but can I fuse Linear with Relu as I saw its possible sequence to fuse
-
If it so,Can you provide the code to fuse
I still don’t think I understand you.
But if you just want to have Linear and ReLU in sequence and callable in one, than this works:
import torch.nn as nn
Linear_ReLU_fusion = nn.Sequential(nn.Linear(in_features, out_features),
nn.ReLU()
)
you could then just call it in one go
out = Linear_ReLU_fusion(x)
e.g.
import torch.nn as nn
Linear_ReLU_fusion = nn.Sequential(nn.Linear(3072, 10),
nn.ReLU()
)
x = torch.rand(1, 3, 32, 32)
x = x.view(-1, 3072)
out = Linear_ReLU_fusion(x)
works fine!
Can I do this to the module wrapped in an sequential?
I don’t really understand the last question.
However, as was already said, you can build “blocks” e.g. via nn.Sequential and use it to call the linear layer with a relu activation function.
That being said, it’s not a “fusion” but just a way to write a model.
I’m still unsure, if you want to fuse mathematical operations, e.g. two linear layers:
# sequential approach
y1 = x * w1 + b1
y2 = y1 * w2 + b2
# "fused"
y2 = (x * w1 + b1) * w2 + b2
y2 = x * w1 * w2 + b1 * w2 + b2
y2 = x * w3 + b3
where w3 = w1 * w2 and b3 = b1 * w2 + b2, which wouldn’t be possible, if you have a relu between these layers, or if you are talking about kernel fusion, where you are writing e.g. CUDA kernels to perform multiple operations in a single kernel.
-
that’s what I exactly needed,fusing weights and biases
-
in FC2 layer I have(linear->relu),In FC3 I have(Bnorm->linear)
-
I tried fusing FC2 linear with FC3 Bnorm but fused weights and bias are not correct as my prediction was wrong
-
From your point if we have relu in between we cant fuse, OK i agreed
-
So i am trying to fuse FC3 Bnorm with FC3 Linear(Bnorm->linear) will i able to do it?
-
I am using this formula
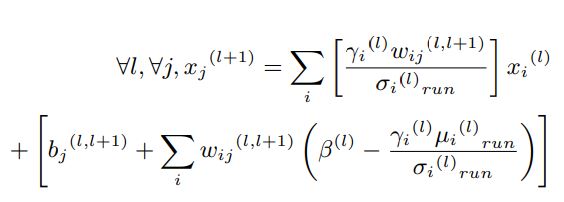
I don’t see how this would be possible, but let’s have a loop at the operations:
# sequential
y1 = x * w1 + b1 # linear
y2 = (y1 - running_mean) / sqrt(running_var + eps) * gamma + beta # batchnorm
# replace y1
y2 = (x * w1 + b1 - running_mean) / sqrt(running_var + eps) * gamma + beta
If you multiply gamma into the left brackets, you would mix the running_mean with a trainable parameter, so how should this “fusion” look like?
-
I want to know this example what u have gave is 1st is linear and then Bnorm?
-
Will be any change if BNorm comes 1st and then Linear?
In your explaination, you have shown with Linear followed by batchnorm.
Can we fuse even if batchnorm comes first followed by Linear
Hi @ptrblck,I have fused linear and bnorm using above formula,I am able to do it,prediction is correct by using fused weights and bias. I am getting all values negative (output of fused layer),that is the linear layer(last layer),can it be possible to get all values negative?