I’m trying to train a GAN on a relatively small dataset of clothing. My dataset is very specific and made up of small girl dresses from one particular brand. It consists of 206 items of dimension 96x72x3. Here are a few examples:






I’ve tried a standard architecture for generator and discriminator as below on a vanilla GAN and LSGAN.
LSGAN Generator: ( For a vanilla GAN, the last sigmoid layer is swapped with tanh. cnnresize and view are my own classes that help with resizing))
Sequential(
(0): Linear(in_features=20, out_features=304384, bias=True)
(1): unView(
)
(2): ConvTranspose2d(64, 64, kernel_size=(5, 5), stride=(1, 1))
(3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True)
(4): ReLU()
(5): ConvTranspose2d(64, 128, kernel_size=(5, 5), stride=(1, 1))
(6): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True)
(7): ReLU()
(8): ConvTranspose2d(128, 128, kernel_size=(3, 3), stride=(1, 1))
(9): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True)
(10): ReLU()
(11): ConvTranspose2d(128, 3, kernel_size=(5, 5), stride=(1, 1))
(12): View(
)
(13): Sigmoid()
)
LSGAN Discriminator: ( For a vanilla GAN, sigmoid is added to the end here. cnnresize and view are my own classes that help with resizing)
Sequential(
(0): cnnresize(
)
(1): Conv2d(3, 128, kernel_size=(5, 5), stride=(2, 2))
(2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True)
(3): ReLU()
(4): Conv2d(128, 48, kernel_size=(5, 5), stride=(2, 2))
(5): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True)
(6): ReLU()
(7): Conv2d(48, 64, kernel_size=(5, 5), stride=(2, 2))
(8): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True)
(9): ReLU()
(10): Conv2d(64, 128, kernel_size=(5, 5), stride=(2, 2))
(11): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True)
(12): ReLU()
(13): View(
)
(14): Dropout(p=0.5)
(15): Linear(in_features=384, out_features=256, bias=True)
(16): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True)
(17): ReLU()
(18): Dropout(p=0.5)
(19): Linear(in_features=256, out_features=128, bias=True)
(20): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True)
(21): ReLU()
(22): Dropout(p=0.5)
(23): Linear(in_features=128, out_features=1, bias=True)
)
Here is my model for vanilla GAN:
# FINAL MODEL TO RUN
# ------------------
def model_gan(x,epochs,mbsize,gen_net,dis_net,gen_lr_rate,dis_lr_rate,gn_mul,no_latent):
#optimizer = torch.optim.Adam(net.parameters(), lr=lr_rate)
#optimizer = torch.optim.RMSprop(net.parameters(), lr=lr_rate)
#optimizer = torch.optim.SGD(net.parameters(), lr=lr_rate, momentum=0.9)
optimizerG = torch.optim.Adam(gen_net.parameters(), lr=gen_lr_rate)
optimizerD = torch.optim.Adam(dis_net.parameters(), lr=dis_lr_rate)
criterion = nn.BCELoss()
global gen_loss
gen_loss = []
global dis_loss
dis_loss = []
# Setting up minibatch features
m = x.size()[0]
mb_list = []
mb_list = list(range(int(m/mbsize)))
if m % mbsize == 0: # if the minibatches can be split up perfectly.
'do nothing'
else:
mb_list.append(mb_list[len(mb_list)-1] + 1)
#noise = sample_noise(m,nz,noise_mode)
#noise = noise.cuda()
for i in range(epochs):
for p in mb_list:
# Mini batch operations
start_index = p*mbsize
end_index = m if p == mb_list[len(mb_list)-1] else p*mbsize + mbsize
# 1. Training the discriminator - Spot real vs fake
# -------------------------------------------------
# 1.1 real data
# -------------
X_mb = x[start_index:end_index]
m_curr = end_index - start_index
y_mb_real = Variable(torch.Tensor(m_curr).fill_(1).float()) # real label = 1
y_mb_real = y_mb_real.cuda()
dis_net.zero_grad()
output = dis_net(X_mb)
output = output.view(-1,)
errD_real = criterion(output, y_mb_real)
errD_real.backward()
# 1.2 fake data
# -------------
noise = Variable(torch.randn(m_curr,no_latent)).cuda()
noise = noise.cuda()
fake_data = gen_net(noise)
y_mb_fake = Variable(torch.Tensor(m_curr).fill_(0).float()) # fake label = 0
y_mb_fake = y_mb_fake.cuda()
output = dis_net(fake_data.detach())
output = output.view(-1,)
errD_fake = criterion(output, y_mb_fake)
errD_fake.backward()
# Updating D network
errD = errD_real + errD_fake
dis_loss.append(errD.data[0])
optimizerD.step()
# 2. Training the generator - making it generate more realistic images
# --------------------------------------------------------------------
for g in range(gn_mul):
gen_net.zero_grad()
output = dis_net(fake_data)
output = output.view(-1,)
errG = criterion(output, y_mb_real)
gen_loss.append(errG.data[0])
errG.backward(retain_graph=True)
optimizerG.step()
# Printing loss
print('Epoch ' + str(i+1) + ', minibatch ' + str(p+1) + ' of ' + str(len(mb_list)) + ' -- Dis_loss: ' + str(errD.data[0]) + ', Gen_loss: ' + str(errG.data[0]))
Here is my LSGAN model:
# FINAL MODEL TO RUN
# ------------------
def model_lsgan(x,epochs,mbsize,gen_net,dis_net,gen_lr_rate,dis_lr_rate,gn_mul,no_latent):
#optimizer = torch.optim.Adam(net.parameters(), lr=lr_rate)
#optimizer = torch.optim.RMSprop(net.parameters(), lr=lr_rate)
#optimizer = torch.optim.SGD(net.parameters(), lr=lr_rate, momentum=0.9)
optimizerG = torch.optim.Adam(gen_net.parameters(), lr=gen_lr_rate)
optimizerD = torch.optim.Adam(dis_net.parameters(), lr=dis_lr_rate)
m = x.shape[0]
#initial_noise = Variable(torch.randn(m,no_latent)).cuda()
global gen_loss
gen_loss = []
global dis_loss
dis_loss = []
# Setting up minibatch features
m = x.size()[0]
mb_list = []
mb_list = list(range(int(m/mbsize)))
if m % mbsize == 0: # if the minibatches can be split up perfectly.
'do nothing'
else:
mb_list.append(mb_list[len(mb_list)-1] + 1)
for i in range(epochs):
for p in mb_list:
# Mini batch operations
start_index = p*mbsize
end_index = m if p == mb_list[len(mb_list)-1] else p*mbsize + mbsize
# 1. Training the discriminator - Spot real vs fake
# -------------------------------------------------
# 1.1 real data
# -------------
X_mb = x[start_index:end_index]
m_curr = end_index - start_index
y_mb_real = Variable(torch.Tensor(m_curr).fill_(1).float()) # real label = 1
y_mb_real = y_mb_real.cuda()
dis_net.zero_grad()
output = dis_net(X_mb)
output = output.view(-1,)
errD_real = torch.mean((output-1)**2)
# 1.2 fake data
# -------------
noise = Variable(torch.randn(m_curr,no_latent)).cuda()
fake_data = gen_net(noise)
y_mb_fake = Variable(torch.Tensor(m_curr).fill_(0).float()) # fake label = 0
y_mb_fake = y_mb_fake.cuda()
output = dis_net(fake_data.detach())
output = output.view(-1,)
errD_fake = torch.mean(output**2)
# Updating D network
errD = 0.5 * (errD_real + errD_fake)
errD.backward()
dis_loss.append(errD.data[0])
optimizerD.step()
# 2. Training the generator - making it generate more realistic images
# --------------------------------------------------------------------
for g in range(gn_mul):
gen_net.zero_grad()
output = dis_net(fake_data)
output = output.view(-1,)
errG = 0.5 * torch.mean((output-1)**2)
gen_loss.append(errG.data[0])
errG.backward(retain_graph=True)
optimizerG.step()
# Printing loss
print('Epoch ' + str(i+1) + ', minibatch ' + str(p+1) + ' of ' + str(len(mb_list)) + ' -- Dis_loss: ' + str(errD.data[0]) + ', Gen_loss: ' + str(errG.data[0]))
Even after 5000 epochs, the generator does not converge. Here’s a snapshot of generator and discriminator losses.
Generator Loss:
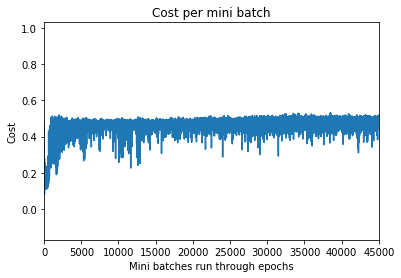
Discriminator loss:
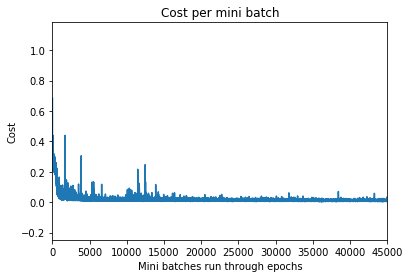
Results sampling code:
# GAN Sampling
# ------------
gen_model = gen_model.eval()
dis_model = dis_model.eval()
h,w,c = 96,72,3
gen_image = gen_model(fixed_noise[0:10].cuda()).view(-1,c,h,w)
gen_image = gen_image.cpu().data.numpy()
gen_image = np.swapaxes(gen_image,1,3)
gen_image = np.swapaxes(gen_image,1,2)
All results are the same as the below yellow blob:

I know that my training set is small but I also know that it is possible to train a GAN on a training set of similar size (reference : Pokemon GAN at this link. Apparently a WGAN trained on a dataset of around 150 pokemons)
I’m new to GANS and my future work relies heavily on GANs. It seems like I’m missing something fundamental. Would greatly appreciate any help in here please.