I have been trying to train a DF-GAN for text-to-image generation. However, after training for a while, the losses become NaN and after that the model does not recover from it. I am using Mixed Precision Training to decrease the training time and increase the batch_size.
Currently, on a V100 GPU (on Google Cloud), each epoch takes about 3 mins with mixed precision enabled. On disabling mixed precision, each epoch takes around 10 mins. So there’s no other option but to enable the mixed precision training.
Before DF-GAN, I was training StackGAN model and experienced the same behavior. I am not understanding as to why this is occurring. I looked up the documentation for mixed precision training for models with multiple optimisers and gradient penalties. I incorporated all the changes that the documentation recommended to do but I could not find any improvements.
I will display the loss curves and the images generated by model after training DF-GAN for a while with MP enabled.
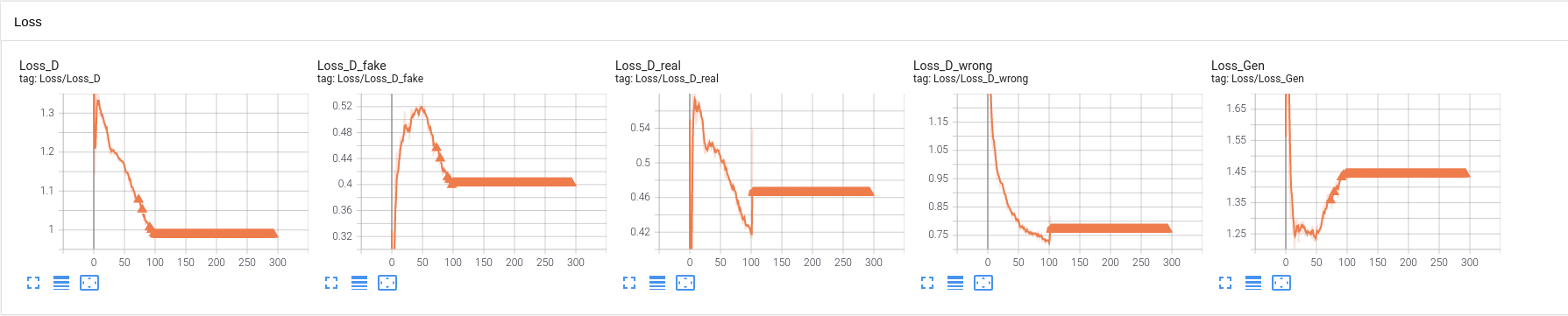
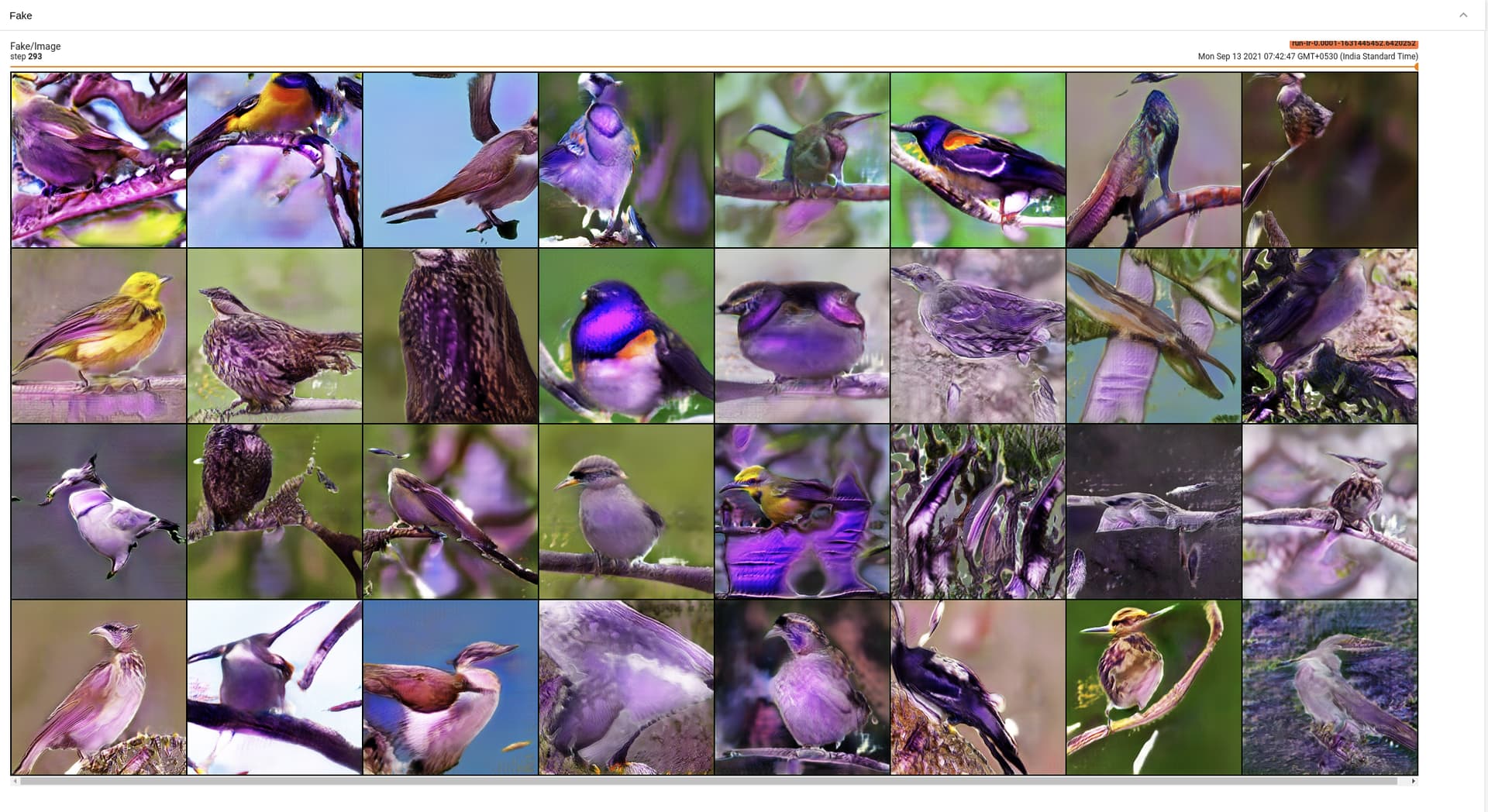
The pictures were not purplish until the NaNs started to occur.
Below is the training configs that I am using to train the model.
cudnn.benchmark = True
class TrainingConfig:
gen_learning_rate = 0.0001
disc_learning_rate = 0.0004
epsilon = 1e-8
betas=(0.00,0.9)
max_epochs = 600
num_workers = 6
batch_size = 32
drop_last=True
shuffle = True
pin_memory = True
ckpt_dir = "./DF-GAN-v1/"
gen_ckpt_path = None
disc_ckpt_path = None
verbose = True
device = "cuda"
logdir = "dfganv1"
snap_shot = 20
def __init__(self,**kwargs) -> None:
for key,value in kwargs.items():
setattr(self,key,value)
Below is the training loop code for training the model.
def run_epoch(split):
is_train = split == "train"
if is_train:
generator.train()
discriminator.train()
else:
generator.eval()
discriminator.eval()
data = self.train_dataset if is_train else self.test_dataset
loader = DataLoader(dataset=data, batch_size=config.batch_size,
shuffle=config.shuffle,
pin_memory=config.pin_memory,
num_workers=config.num_workers,
drop_last=config.drop_last)
lossesD, lossesD_real, lossesD_wrong, lossesD_fake, losses_kl, losses_gen = [], [], [], [], [], []
pbar = tqdm(enumerate(loader),total=len(loader)) if is_train and config.verbose else enumerate(loader)
for it, data in pbar:
# place data on the correct device
images,captions,caption_len,class_ids, keys = prepare_data(data)
hidden = text_encoder.init_hidden(config.batch_size)
# words_embs: batch_size x nef x seq_len
# sent_emb: batch_size x nef
word_embeddings, sentence_embeddings = text_encoder(captions, caption_len, hidden)
word_embeddings, sentence_embeddings = word_embeddings.detach(), sentence_embeddings.detach()
images = images[0].to(self.device)
noise = torch.randn(config.batch_size,100,device=self.device)
disc_optimizer.zero_grad(set_to_none=True)
gen_optimizer.zero_grad(set_to_none=True)
with amp.autocast():
real_features = discriminator(images)
output = discriminator.COND_DNET(real_features, sentence_embeddings)
errorD_real = F.relu(1.0-output).mean()
with amp.autocast():
output = discriminator.COND_DNET(real_features[:(config.batch_size-1)],sentence_embeddings[1:(config.batch_size)])
errorD_wrong = F.relu(1.0+output).mean()
#synthesis fake images
with amp.autocast():
fake_images = generator(noise,sentence_embeddings)
fake_features = discriminator(fake_images.detach())
output = discriminator.COND_DNET(fake_features,sentence_embeddings)
errorD_fake = F.relu(1.0+output).mean()
errorD = errorD_real + (errorD_wrong + errorD_fake) * 0.5
scaler.scale(errorD).backward()
scaler.step(disc_optimizer)
scaler.update()
#MA-GP (gradient penalty)
interpolated = (images.data).requires_grad_()
sent_inter = (sentence_embeddings.data).requires_grad_()
with amp.autocast():
features = discriminator(interpolated)
out = discriminator.COND_DNET(features,sent_inter)
grads = torch.autograd.grad(outputs=out,
inputs=(interpolated,sent_inter),
grad_outputs=torch.ones(out.size()).cuda(),
retain_graph=True,
create_graph=True,
only_inputs=True)
grad0 = grads[0].view(grads[0].size(0), -1)
grad1 = grads[1].view(grads[1].size(0), -1)
grad = torch.cat((grad0,grad1),dim=1)
grad_l2norm = torch.sqrt(torch.sum(grad ** 2, dim=1))
d_loss_gp = torch.mean((grad_l2norm) ** 6)
d_loss = 2.0 * d_loss_gp
disc_optimizer.zero_grad(set_to_none=True)
gen_optimizer.zero_grad(set_to_none=True)
scaler.scale(d_loss).backward()
scaler.step(disc_optimizer)
### update G network ###
disc_optimizer.zero_grad(set_to_none=True)
gen_optimizer.zero_grad(set_to_none=True)
with amp.autocast():
features = discriminator(fake_images)
output = discriminator.COND_DNET(features,sentence_embeddings)
errorG = - output.mean()
scaler.scale(errorG).backward()
scaler.step(gen_optimizer)
scaler.update()
lossesD.append(errorD.item())
lossesD_real.append(errorD_real.item())
lossesD_fake.append(errorD_fake.item())
lossesD_wrong.append(errorD_wrong.item())
losses_gen.append(errorG.item())
Please let me know if the MP sections of my training loop are correct. If not let me know what other options are there to prevent NaN from occuring.
The model used is taken from : GitHub - tobran/DF-GAN: A Simple and Effective Baseline for Text-to-Image Synthesis (CVPR2022 oral)