hi,
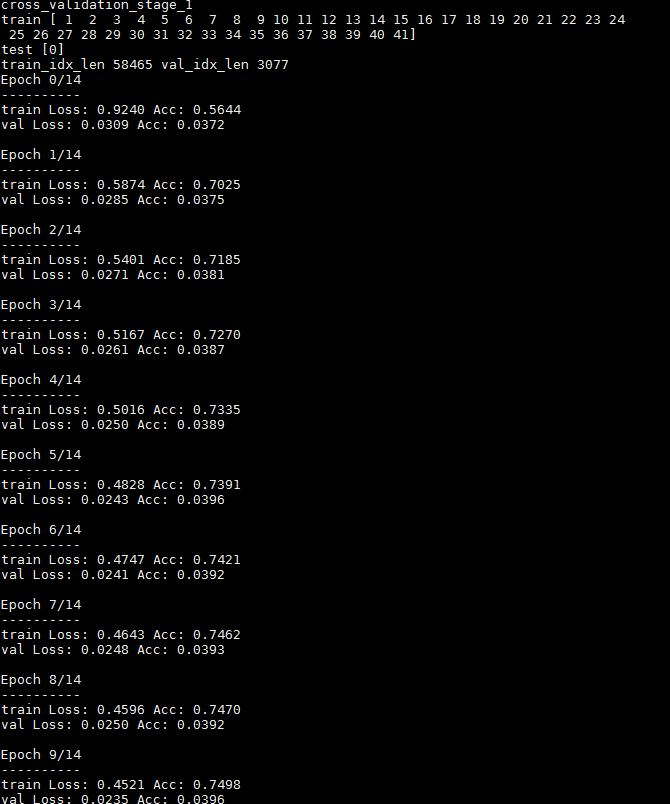
I am using pytorch finetuning tutorial Finetuning Torchvision Models — PyTorch Tutorials 2.2.0+cu121 documentation. the validation set is 5% of training set. The training accuracy is increases but validation accuracy is between 3-5%. what is the error.
#
# Finetuning Torchvision Models
# =============================
#
#
#
#
#
# In[1]:
from __future__ import print_function
from __future__ import division
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import numpy as np
import pandas as pd
import torchvision
from torch.utils.data import DataLoader,Dataset
from torchvision import datasets, models, transforms
from torch.utils.data.sampler import SubsetRandomSampler
import matplotlib.pyplot as plt
import time
import os
import copy
from PIL import Image
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
print("PyTorch Version: ",torch.__version__)
print("Torchvision Version: ",torchvision.__version__)
# In[2]:
from sklearn.model_selection import LeaveOneGroupOut
from sklearn.metrics import confusion_matrix,classification_report
logo=LeaveOneGroupOut()
# In[3]:
# Inputs
# ------
#
# Here are all of the parameters to change for the run. We will use the
# *hymenoptera_data* dataset which can be downloaded
# `here <https://download.pytorch.org/tutorial/hymenoptera_data.zip>`__.
# This dataset contains two classes, **bees** and **ants**, and is
# structured such that we can use the
# `ImageFolder <https://pytorch.org/docs/stable/torchvision/datasets.html#torchvision.datasets.ImageFolder>`__
# dataset, rather than writing our own custom dataset. Download the data
# and set the ``data_dir`` input to the root directory of the dataset. The
# ``model_name`` input is the name of the model you wish to use and must
# be selected from this list:
#
# ::
#
# [resnet, alexnet, vgg, squeezenet, densenet, inception]
#
# The other inputs are as follows: ``num_classes`` is the number of
# classes in the dataset, ``batch_size`` is the batch size used for
# training and may be adjusted according to the capability of your
# machine, ``num_epochs`` is the number of training epochs we want to run,
# and ``feature_extract`` is a boolean that defines if we are finetuning
# or feature extracting. If ``feature_extract = False``, the model is
# finetuned and all model parameters are updated. If
# ``feature_extract = True``, only the last layer parameters are updated,
# the others remain fixed.
#
#
#
# In[4]:
# Top level data directory. Here we assume the format of the directory conforms
# to the ImageFolder structure
filepath = "../30_sec_cwt_images.xlsx"
df=pd.read_excel(filepath)
# Models to choose from [resnet, alexnet, vgg, squeezenet, densenet, inception]
model_name = "squeezenet"
# Number of classes in the dataset
num_classes = 5
# Batch size for training (change depending on how much memory you have)
batch_size = 128
# Number of epochs to train for
num_epochs = 5
# Flag for feature extracting. When False, we finetune the whole model,
# when True we only update the reshaped layer params
feature_extract = False
use_parallel=True
# Helper Functions
# ----------------
#
# Before we write the code for adjusting the models, lets define a few
# helper functions.
#
# Model Training and Validation Code
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
#
# The ``train_model`` function handles the training and validation of a
# given model. As input, it takes a PyTorch model, a dictionary of
# dataloaders, a loss function, an optimizer, a specified number of epochs
# to train and validate for, and a boolean flag for when the model is an
# Inception model. The *is_inception* flag is used to accomodate the
# *Inception v3* model, as that architecture uses an auxiliary output and
# the overall model loss respects both the auxiliary output and the final
# output, as described
# `here <https://discuss.pytorch.org/t/how-to-optimize-inception-model-with-auxiliary-classifiers/7958>`__.
# The function trains for the specified number of epochs and after each
# epoch runs a full validation step. It also keeps track of the best
# performing model (in terms of validation accuracy), and at the end of
# training returns the best performing model. After each epoch, the
# training and validation accuracies are printed.
#
#
#
# In[5]:
def train_model(model, dataloaders, criterion, optimizer,scheduler, num_epochs=25, is_inception=False):
since = time.time()
val_acc_history = []
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'val']:
if phase == 'train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
# Get model outputs and calculate loss
# Special case for inception because in training it has an auxiliary output. In train
# mode we calculate the loss by summing the final output and the auxiliary output
# but in testing we only consider the final output.
if is_inception and phase == 'train':
# From https://discuss.pytorch.org/t/how-to-optimize-inception-model-with-auxiliary-classifiers/7958
outputs, aux_outputs = model(inputs)
loss1 = criterion(outputs, labels)
loss2 = criterion(aux_outputs, labels)
loss = loss1 + 0.4*loss2
else:
outputs = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(dataloaders[phase].dataset)
epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
# deep copy the model
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
if phase == 'val':
val_acc_history.append(epoch_acc)
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# load best model weights
model.load_state_dict(best_model_wts)
return model, val_acc_history
# In[6]:
def test(model,criterion,dataloaders_dict):
#monitor test loss and accuracy
test_loss=0.
correct=0.
total=0.
y_pred=np.array([])
y_true=np.array([])
with torch.no_grad():
for inputs, labels in dataloaders_dict['test']:
inputs = inputs.to(device)
labels = labels.to(device)
# s #forward pass: compute predicted outputs by passing input to model
output=model(inputs)
#calculate loss
loss=criterion(output,labels)
_,preds=torch.max(output.data,1)
total+=labels.size(0)
correct+=torch.sum(preds==labels.data).sum()
y_pred=np.hstack([y_pred,preds.numpy()])
y_true=np.hstack([y_true,labels.numpy()])
#preds=preds.numpy()
#y_pred.append(preds)
cm= confusion_matrix(y_true,y_pred)
print(confusion_matrix(y_true,y_pred))
print('accuracy',accuracy_score(y_true,y_pred))
print(classification_report(y_true,y_pred))
#print('accuracy of network on test images: %d' %(100*correct/total))
return cm
# Set Model Parameters’ .requires_grad attribute
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
#
# This helper function sets the ``.requires_grad`` attribute of the
# parameters in the model to False when we are feature extracting. By
# default, when we load a pretrained model all of the parameters have
# ``.requires_grad=True``, which is fine if we are training from scratch
# or finetuning. However, if we are feature extracting and only want to
# compute gradients for the newly initialized layer then we want all of
# the other parameters to not require gradients. This will make more sense
# later.
#
#
#
# In[7]:
def set_parameter_requires_grad(model, feature_extracting):
if feature_extracting:
for param in model.parameters():
param.requires_grad = False
# Initialize and Reshape the Networks
# -----------------------------------
#
# Now to the most interesting part. Here is where we handle the reshaping
# of each network. Note, this is not an automatic procedure and is unique
# to each model. Recall, the final layer of a CNN model, which is often
# times an FC layer, has the same number of nodes as the number of output
# classes in the dataset. Since all of the models have been pretrained on
# Imagenet, they all have output layers of size 1000, one node for each
# class. The goal here is to reshape the last layer to have the same
# number of inputs as before, AND to have the same number of outputs as
# the number of classes in the dataset. In the following sections we will
# discuss how to alter the architecture of each model individually. But
# first, there is one important detail regarding the difference between
# finetuning and feature-extraction.
#
# When feature extracting, we only want to update the parameters of the
# last layer, or in other words, we only want to update the parameters for
# the layer(s) we are reshaping. Therefore, we do not need to compute the
# gradients of the parameters that we are not changing, so for efficiency
# we set the .requires_grad attribute to False. This is important because
# by default, this attribute is set to True. Then, when we initialize the
# new layer and by default the new parameters have ``.requires_grad=True``
# so only the new layer’s parameters will be updated. When we are
# finetuning we can leave all of the .required_grad’s set to the default
# of True.
#
# Finally, notice that inception_v3 requires the input size to be
# (299,299), whereas all of the other models expect (224,224).
#
# Resnet
# ~~~~~~
#
# Resnet was introduced in the paper `Deep Residual Learning for Image
# Recognition <https://arxiv.org/abs/1512.03385>`__. There are several
# variants of different sizes, including Resnet18, Resnet34, Resnet50,
# Resnet101, and Resnet152, all of which are available from torchvision
# models. Here we use Resnet18, as our dataset is small and only has two
# classes. When we print the model, we see that the last layer is a fully
# connected layer as shown below:
#
# ::
#
# (fc): Linear(in_features=512, out_features=1000, bias=True)
#
# Thus, we must reinitialize ``model.fc`` to be a Linear layer with 512
# input features and 2 output features with:
#
# ::
#
# model.fc = nn.Linear(512, num_classes)
#
# Alexnet
# ~~~~~~~
#
# Alexnet was introduced in the paper `ImageNet Classification with Deep
# Convolutional Neural
# Networks <https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf>`__
# and was the first very successful CNN on the ImageNet dataset. When we
# print the model architecture, we see the model output comes from the 6th
# layer of the classifier
#
# ::
#
# (classifier): Sequential(
# ...
# (6): Linear(in_features=4096, out_features=1000, bias=True)
# )
#
# To use the model with our dataset we reinitialize this layer as
#
# ::
#
# model.classifier[6] = nn.Linear(4096,num_classes)
#
# VGG
# ~~~
#
# VGG was introduced in the paper `Very Deep Convolutional Networks for
# Large-Scale Image Recognition <https://arxiv.org/pdf/1409.1556.pdf>`__.
# Torchvision offers eight versions of VGG with various lengths and some
# that have batch normalizations layers. Here we use VGG-11 with batch
# normalization. The output layer is similar to Alexnet, i.e.
#
# ::
#
# (classifier): Sequential(
# ...
# (6): Linear(in_features=4096, out_features=1000, bias=True)
# )
#
# Therefore, we use the same technique to modify the output layer
#
# ::
#
# model.classifier[6] = nn.Linear(4096,num_classes)
#
# Squeezenet
# ~~~~~~~~~~
#
# The Squeeznet architecture is described in the paper `SqueezeNet:
# AlexNet-level accuracy with 50x fewer parameters and <0.5MB model
# size <https://arxiv.org/abs/1602.07360>`__ and uses a different output
# structure than any of the other models shown here. Torchvision has two
# versions of Squeezenet, we use version 1.0. The output comes from a 1x1
# convolutional layer which is the 1st layer of the classifier:
#
# ::
#
# (classifier): Sequential(
# (0): Dropout(p=0.5)
# (1): Conv2d(512, 1000, kernel_size=(1, 1), stride=(1, 1))
# (2): ReLU(inplace)
# (3): AvgPool2d(kernel_size=13, stride=1, padding=0)
# )
#
# To modify the network, we reinitialize the Conv2d layer to have an
# output feature map of depth 2 as
#
# ::
#
# model.classifier[1] = nn.Conv2d(512, num_classes, kernel_size=(1,1), stride=(1,1))
#
# Densenet
# ~~~~~~~~
#
# Densenet was introduced in the paper `Densely Connected Convolutional
# Networks <https://arxiv.org/abs/1608.06993>`__. Torchvision has four
# variants of Densenet but here we only use Densenet-121. The output layer
# is a linear layer with 1024 input features:
#
# ::
#
# (classifier): Linear(in_features=1024, out_features=1000, bias=True)
#
# To reshape the network, we reinitialize the classifier’s linear layer as
#
# ::
#
# model.classifier = nn.Linear(1024, num_classes)
#
# Inception v3
# ~~~~~~~~~~~~
#
# Finally, Inception v3 was first described in `Rethinking the Inception
# Architecture for Computer
# Vision <https://arxiv.org/pdf/1512.00567v1.pdf>`__. This network is
# unique because it has two output layers when training. The second output
# is known as an auxiliary output and is contained in the AuxLogits part
# of the network. The primary output is a linear layer at the end of the
# network. Note, when testing we only consider the primary output. The
# auxiliary output and primary output of the loaded model are printed as:
#
# ::
#
# (AuxLogits): InceptionAux(
# ...
# (fc): Linear(in_features=768, out_features=1000, bias=True)
# )
# ...
# (fc): Linear(in_features=2048, out_features=1000, bias=True)
#
# To finetune this model we must reshape both layers. This is accomplished
# with the following
#
# ::
#
# model.AuxLogits.fc = nn.Linear(768, num_classes)
# model.fc = nn.Linear(2048, num_classes)
#
# Notice, many of the models have similar output structures, but each must
# be handled slightly differently. Also, check out the printed model
# architecture of the reshaped network and make sure the number of output
# features is the same as the number of classes in the dataset.
#
#
#
# In[8]:
def initialize_model(model_name, num_classes, feature_extract, use_pretrained=False):
# Initialize these variables which will be set in this if statement. Each of these
# variables is model specific.
model_ft = None
input_size = 0
if model_name == "resnet":
""" Resnet18
"""
model_ft = models.resnet18(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "alexnet":
""" Alexnet
"""
model_ft = models.alexnet(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)
input_size = 224
elif model_name == "vgg":
""" VGG11_bn
"""
model_ft = models.vgg11_bn(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)
input_size = 224
elif model_name == "squeezenet":
""" Squeezenet
"""
if use_pretrained:
model_ft = models.squeezenet1_0()
model_ft.load_state_dict(torch.load("./squeezenet1_0.pth"))
else:
model_ft=models.squeezenet1_0()
set_parameter_requires_grad(model_ft, feature_extract)
model_ft.classifier[1] = nn.Conv2d(512, num_classes, kernel_size=(1,1), stride=(1,1))
model_ft.num_classes = num_classes
input_size = 224
elif model_name == "densenet":
""" Densenet
"""
model_ft = models.densenet121(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier.in_features
model_ft.classifier = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "inception":
""" Inception v3
Be careful, expects (299,299) sized images and has auxiliary output
"""
model_ft = models.inception_v3(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
# Handle the auxilary net
num_ftrs = model_ft.AuxLogits.fc.in_features
model_ft.AuxLogits.fc = nn.Linear(num_ftrs, num_classes)
# Handle the primary net
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs,num_classes)
input_size = 299
else:
print("Invalid model name, exiting...")
exit()
return model_ft, input_size
# In[9]:
# Initialize the model for this run
#model_ft, input_size = initialize_model(model_name, num_classes, feature_extract, use_pretrained=True)
# Print the model we just instantiated
#print(model_ft)
# Load Data
# ---------
#
# Now that we know what the input size must be, we can initialize the data
# transforms, image datasets, and the dataloaders. Notice, the models were
# pretrained with the hard-coded normalization values, as described
# `here <https://pytorch.org/docs/master/torchvision/models.html>`__.
#
#
#
# In[10]:
# Detect if we have a GPU available
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# In[11]:
class MyDataset(Dataset):
def __init__(self,filepath,indices=None,transform=None):
self.data=pd.read_excel(filepath).values
#if indices is not None:
# self.data=self.data[indices,:]
#imagepath
self.image_arr=self.data[:,0]
#labels
self.label_arr=self.data[:,1]
#groups
self.groups=self.data[:,2]
#calculate length
self.data_len=len(self.data)
self.transform=transform
def __len__(self):
return len(self.data)
def __getitem__(self,idx):
img_name=str(self.image_arr[idx])
img_name='../data/'+img_name
image=Image.open(img_name)
label=self.label_arr[idx]
if self.transform is not None:
image=self.transform(image)
return image,label
# Create the Optimizer
# --------------------
#
# Now that the model structure is correct, the final step for finetuning
# and feature extracting is to create an optimizer that only updates the
# desired parameters. Recall that after loading the pretrained model, but
# before reshaping, if ``feature_extract=True`` we manually set all of the
# parameter’s ``.requires_grad`` attributes to False. Then the
# reinitialized layer’s parameters have ``.requires_grad=True`` by
# default. So now we know that *all parameters that have
# .requires_grad=True should be optimized.* Next, we make a list of such
# parameters and input this list to the SGD algorithm constructor.
#
# To verify this, check out the printed parameters to learn. When
# finetuning, this list should be long and include all of the model
# parameters. However, when feature extracting this list should be short
# and only include the weights and biases of the reshaped layers.
#
#
#
# In[12]:
dataset_mean = [ 0.5254, 0.5553, 0.8446]
dataset_std = [ 0.3255, 0.3164, 0.1453]
#transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
train_transform = transforms.Compose([transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225]) ])
val_transform = transforms.Compose([transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225])
])
test_transform = transforms.Compose([transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225])
])
# Run Training and Validation Step
# --------------------------------
#
# Finally, the last step is to setup the loss for the model, then run the
# training and validation function for the set number of epochs. Notice,
# depending on the number of epochs this step may take a while on a CPU.
# Also, the default learning rate is not optimal for all of the models, so
# to achieve maximum accuracy it would be necessary to tune for each model
# separately.
#
#
#
# In[ ]:
cv=0
cm=np.zeros((5,5))
acc=[]
for train_idx,test_idx in logo.split(X=df['filename'],y=None,groups=df['groups']):
#print(train_idx,test_idx)
#print(len(train_idx))
cv=cv+1
print('cross_validation_stage_'+str(cv))
#print(len(test_idx))
print('train',np.unique(df['groups'][train_idx]))
print('test',np.unique(df['groups'][test_idx]))
np.random.shuffle(train_idx)
num_train=len(train_idx)
valid_size=0.05
split = int(np.floor(valid_size * num_train))
#train_idx, val_idx = train_idx[split:], train_idx[:split]
train_idx, val_idx = train_idx[split:], train_idx[:split]
print('train_idx_len',len(train_idx),'val_idx_len',len(val_idx))
#define sampler for obtaining training and validation batches
train_sampler=SubsetRandomSampler(train_idx)
test_sampler=SubsetRandomSampler(test_idx)
val_sampler=SubsetRandomSampler(val_idx)
dataset_train=MyDataset(filepath, transform=train_transform)
dataset_test=MyDataset(filepath,transform=test_transform)
dataset_val=MyDataset(filepath,transform=val_transform)
train_loader=DataLoader(dataset_train,batch_size=batch_size,sampler=train_sampler,num_workers=4)
#print(len(train_loader))
test_loader=DataLoader(dataset_test,batch_size=batch_size,sampler=test_sampler,num_workers=4)
#print(len(test_loader))
val_loader=DataLoader(dataset_val,batch_size=batch_size,sampler=val_sampler,num_workers=4)
#print(len(val_loader))
dataloaders_dict={'train':train_loader,'val':val_loader,'test':test_loader}
#for epoch in range(1,num_epochs+1):
# Train and evaluate
model_ft, input_size = initialize_model(model_name, num_classes, feature_extract=False, use_pretrained=True)
if use_parallel:
model_ft=nn.DataParallel(model_ft,device_ids=[0,1,2,3])
model_ft=model_ft.to(device)
params_to_update = model_ft.parameters()
# Observe that all parameters are being optimized
#optimizer_ft = optim.SGD(params_to_update, lr=0.001, momentum=0.9)
optimizer_ft = optim.Adam(params_to_update, lr=0.0001)
exp_lr_scheduler=lr_scheduler.StepLR(optimizer_ft,step_size=7,gamma=0.1)
# Setup the loss fxn
criterion = nn.CrossEntropyLoss()
#criterion = nn.NLLLoss()
model_ft, hist = train_model(model_ft, dataloaders_dict, criterion, optimizer_ft, exp_lr_scheduler, num_epochs=num_epochs, is_inception=(model_name=="inception"))
torch.save(model_ft.state_dict(),'model_ft_'+model_name+str(cv)+'.pt')
conf_mat=test(model_ft,criterion,dataloaders_dict)
cm=cm+conf_mat
# comparision with model trained from scratch
# Initialize the non-pretrained version of the model used for this run
scratch_model,_ = initialize_model(model_name, num_classes, feature_extract=False, use_pretrained=False)
if use_parallel:
scratch_model=nn.DataParallel(scratch_model, device_ids=[0,1,2,3])
scratch_model = scratch_model.to(device)
#scratch_optimizer = optim.SGD(scratch_model.parameters(), lr=0.001,momentum=0.9)
scratch_optimizer = optim.Adam(scratch_model.parameters(), lr=0.0001)
scratch_exp_lr_scheduler=lr_scheduler.StepLR(scratch_optimizer,step_size=7,gamma=0.1)
#scratch_criterion = nn.NLLLoss()
scratch_criterion = nn.CrossEntropyLoss()
_,scratch_hist = train_model(scratch_model, dataloaders_dict, scratch_criterion, scratch_optimizer,scratch_exp_lr_scheduler, num_epochs=num_epochs, is_inception=(model_name=="inception"))
# Plot the training curves of validation accuracy vs. number
# of training epochs for the transfer learning method and
# the model trained from scratch
ohist = []
shist = []
ohist = [h.cpu().numpy() for h in hist]
shist = [h.cpu().numpy() for h in scratch_hist]
plt.title("Validation Accuracy vs. Number of Training Epochs")
plt.xlabel("Training Epochs")
plt.ylabel("Validation Accuracy")
plt.plot(range(1,num_epochs+1),ohist,label="Pretrained")
plt.plot(range(1,num_epochs+1),shist,label="Scratch")
plt.ylim((0,1.))
plt.xticks(np.arange(1, num_epochs+1, 1.0))
plt.legend()
plt.savefig('cross_validation_stage'+str(cv))
break
print(cm)