Can u check for each value in tensor x any values nan using isNAN() funciton.
Which PyTorch version are you using at the moment?
The latest.
I just solved this problem. It was just the transformation I did on the data while loading it.
I am facing another problem right now. the optimizer.step() is not doing anything and thus the loss is not getting updated
Could you elaborate, what did the transformation do to the data?
Did it generate NAN values after transformations and were passed to NN or was it some other issue?
I did not really know what it did.
I just changed the transformations and all went fine.
Do you have any idea why optimizer.step() is not doing anything ?
If the question is regarding:
could you please create a new topic for it, please?
1 Like
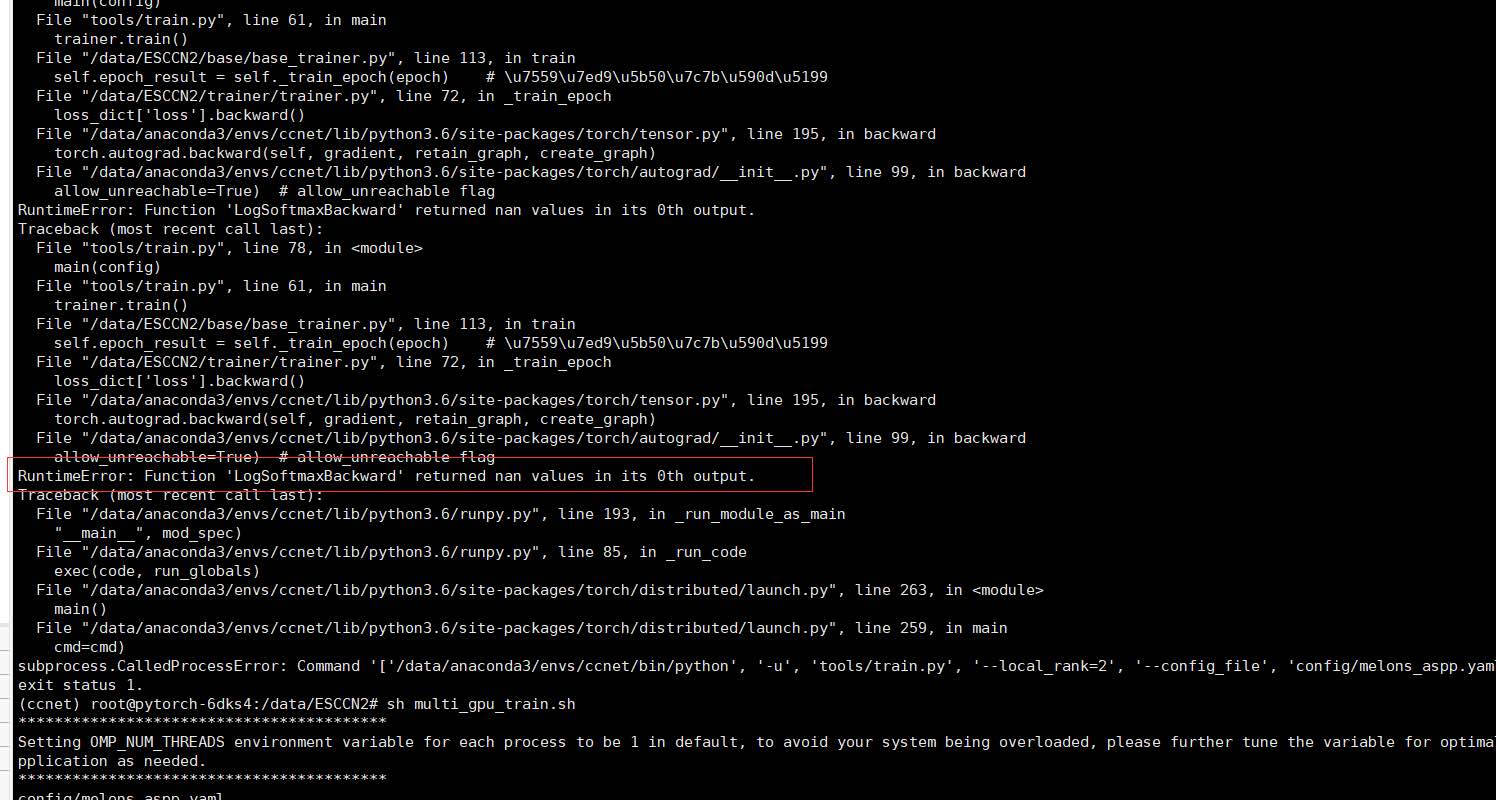
can you help me? I have been stuck with this problem for several days, I continue to simplify the network structure and this problem still occurs @ptrblck
Check all inputs for valid values using torch.isfinite(tensor) as well as the loss.
If that doesn’t help, check all gradients and parameters in each iteration and make sure they all have valid values.
1 Like
I iterated over a few epochs, sometimes even after dozens of epochs. I use torch.autograd.detect_anomaly(), and then the first prompt that nan is in softmax.
This could exclude the input, but I would nevertheless check if, as your preprocessing might create invalid values. Also, as described, I would then check the output, loss, gradients, and parameters.
My preprocessing is common preprocessing for semantic segmentation, and I am outputting the maxvalue and minvalue which input of bceloss.
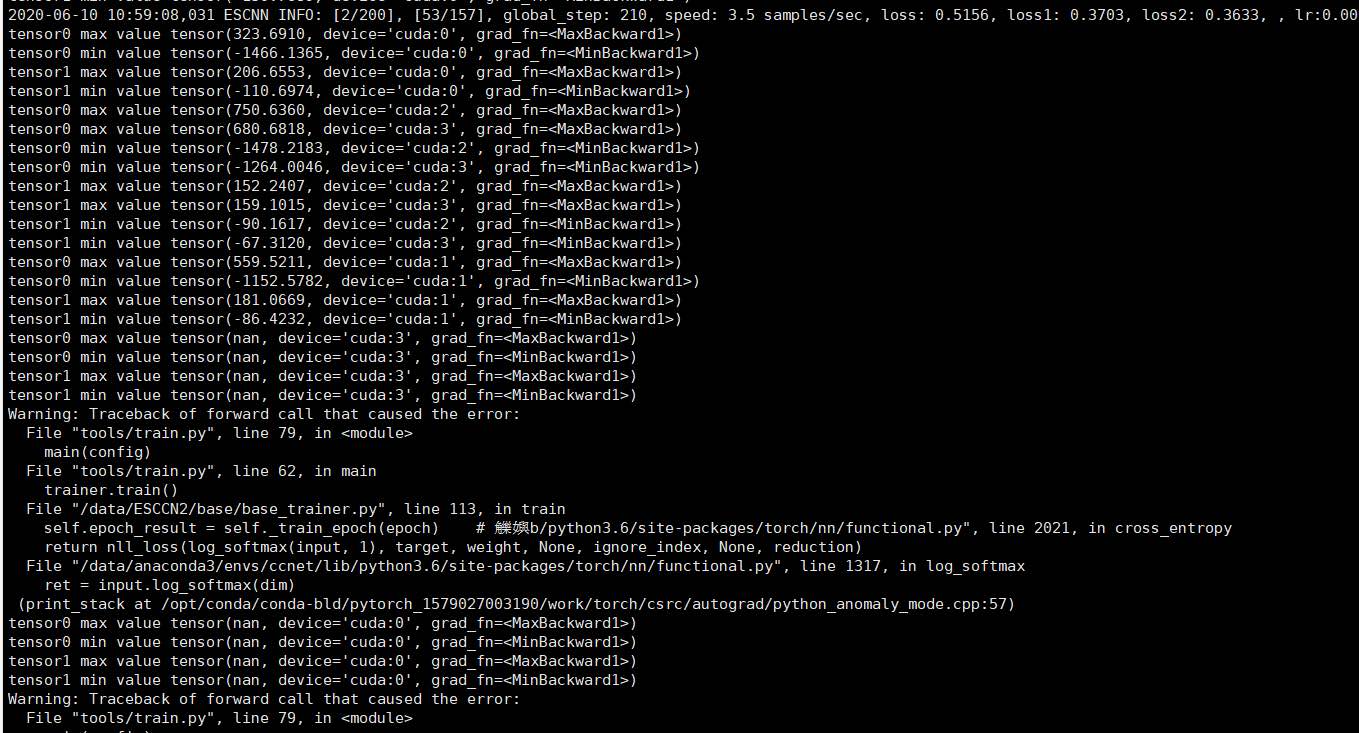
Do you mean the loss is a NaN value or which input is NaN?
If the loss get a NaN value, you might overflow in a certain layer.
Since the error is reproducible, I would recommend to store the state_dict of the model in each step as well as the input tensors, so that you could trigger the NaN output in a single step.
Once you’ve isolated it, you could use forward hooks to see, which layer creates the first NaN output.
1 Like
I tried a single gpu and and set bz=2 to determine whether it was an input problem. However, I tried four or five words, each time the nan of images are different, so this error should have nothing to do with the input, below I will store it in your way, and then print to see that there is a problem with that layer.
If bn caused this problem, how should I solve it?
If you think that a batchnorm layer might create an issue, you could increase the eps value.
However, how did you isolate it to the batchnorm layers?
just only bz = 5 or 10 ,one gpu can work, but muti-gpu can not work 。
It is not a problem of bz, the weight update is unstable, and the gradient backpropagates, resulting in gradient explosion. But I tried gradient cropping before, and it didn’t work. Is there any other way to solve this problem?
Are you using a manual multi-GPU implementation or e.g. nn.DataParallel?
In the latter case, you should get the same gradients as seen in this code snippet:
import torch
import torch.nn as nn
import torchvision.models as models
# Single GPU run
model = models.resnet18().cuda(1).eval()
x = torch.randn(8, 3, 224, 224).cuda(1)
out = model(x)
out.mean().backward()
ref_grads = {}
for name, param in model.named_parameters():
ref_grads[name] = param.grad.clone()
model.zero_grad()
# DataParallel comparison
model = nn.DataParallel(model, device_ids=[1, 2])
out_dp = model(x)
out_dp.mean().backward()
print('output ', (out - out_dp).abs().max())
dp_params = dict(model.module.named_parameters())
for key in ref_grads:
ref_grad = ref_grads[key]
dp_grad = dp_params[key].grad
if torch.allclose(ref_grad, dp_grad):
print(key, ' allclose')
else:
print(key, ' NOT allclose')
print(key, (ref_grads[key] - dp_params[key].grad).abs().max())
Note that the input batch will be split in dim0 and each chunk will be sent to the corresponding device.
If your training is sensitive to small batch sizes, try to increase the batch size.