I want to implement a graphic ram efficient trainning programs,but get threading lock problems . here is the steps .
1 replicate my modules to 4 GPUS .
2 caculate forward and loss in this 4 GPUS.
3 caculate backward in 4 GPUS , here comes the problem the backward step cannot be parallel .
According debug ,i find when run loss.backward() in GPU1 , the modules in gpu1 which copy from default model ,it parameter’s grad is None ,and default model get the grad that gpu1 actually caculated
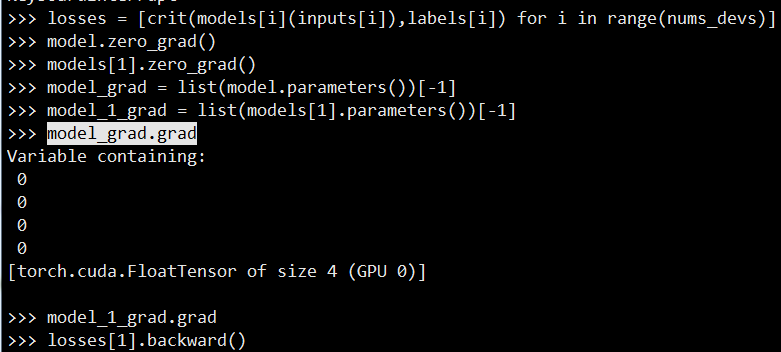
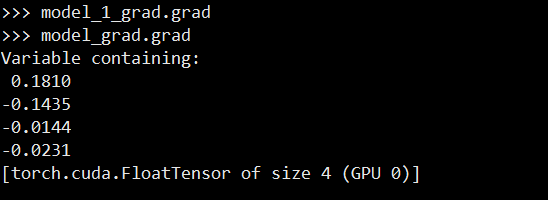
models[1] is copy from model