I’m trying to build a model that trains Conv2d layers on the center crop of a larger image while using the same layers to produce a feature map from the full size image without calculating gradients. I can do this as follows:
x_crop = x[..., offset:-offset, offset:-offset]
x_crop = self.conv_layers(x_crop)
with torch.no_grad():
x = self.conv_layers(x)
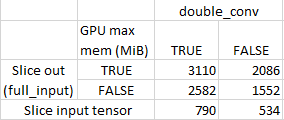
But I’d like to share batchnorm stats and/or reduce the redundant computation of the center patch.
To do this I believe I should be able to slice a center crop from the output feature map of the full image, then .detach() the full image feature map. This works though a single conv layer but the memory use jumps with more than one to about the same as backpropagating though the full feature map.
import torch
from torch import nn
class DualModel(nn.Module):
def __init__(self, in_size, out_size, double_conv, full_input):
super().__init__()
self.double_conv = double_conv
self.full_input = full_input
self.in_size = in_size
self.out_size = out_size
self.conv_layer1 = nn.Sequential(
nn.Conv2d(1, 32, 3, 1, 1, bias=True),
nn.LeakyReLU(inplace=False),
nn.Dropout2d(p=0.1),
)
self.conv_layer2 = nn.Sequential(
nn.Conv2d(32, 32, 3, 1, 1, bias=True),
nn.LeakyReLU(inplace=False),
nn.Dropout2d(p=0.1),
)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.final = nn.Conv2d(in_channels=32, out_channels=1, kernel_size=1, stride=1)
def forward(self, x_c):
offset = int((self.in_size - self.out_size)/2)
x_c = self.conv_layer1(x_c)
if self.double_conv:
x_c = self.conv_layer2(x_c)
if not self.full_input:
x_c = x_c[..., offset:-offset, offset:-offset]
return self.final(x_c)
def to_MiB(x):
return x/1024**2
def estimate_memory_training(model, sample_input, optimizer_type=torch.optim.Adam, use_amp=False, device=0):
"""Predict the maximum memory usage of the model.
Args:
optimizer_type (Type): the class name of the optimizer to instantiate
model (nn.Module): the neural network model
sample_input (torch.Tensor): A sample input to the network. It should be
a single item, not a batch, and it will be replicated batch_size times.
batch_size (int): the batch size
use_amp (bool): whether to estimate based on using mixed precision
device (torch.device): the device to use
"""
# Reset model and optimizer
model.cpu()
optimizer = optimizer_type(model.parameters(), lr=.001)
a = torch.cuda.memory_allocated(device)
model.to(device)
b = torch.cuda.memory_allocated(device)
model_memory = b - a
model_input = sample_input
output = model(model_input.to(device)).sum()
c = torch.cuda.memory_allocated(device)
if use_amp:
amp_multiplier = .5
else:
amp_multiplier = 1
forward_pass_memory = (c - b)*amp_multiplier
gradient_memory = model_memory
if isinstance(optimizer, torch.optim.Adam):
o = 2
elif isinstance(optimizer, torch.optim.RMSprop):
o = 1
elif isinstance(optimizer, torch.optim.SGD):
o = 0
elif isinstance(optimizer, torch.optim.Adagrad):
o = 1
else:
raise ValueError("Unsupported optimizer. Look up how many moments are" +
"stored by your optimizer and add a case to the optimizer checker.")
gradient_moment_memory = o*gradient_memory
total_memory = model_memory + forward_pass_memory + gradient_memory + gradient_moment_memory
return total_memory
def test_memory_training(model, in_size, optimizer_type=torch.optim.SGD, use_amp=False, device=0):
sample_input = torch.randn(*in_size, dtype=torch.float32)
max_mem_est = estimate_memory_training(model, sample_input, optimizer_type=optimizer_type, use_amp=use_amp, device=device+1)
print(f"Maximum Memory Estimate: {to_MiB(max_mem_est)} MiB")
optimizer = optimizer_type(model.parameters(), lr=.001)
print(f"Beginning mem: {to_MiB(torch.cuda.memory_allocated(device))}", "Note - this may be higher than 0, which is due to PyTorch caching. Don't worry too much about this number")
model.to(device)
print(f"After model to device: {to_MiB(torch.cuda.memory_allocated(device))}")
for i in range(3):
optimizer.zero_grad(set_to_none=True)
print("Iteration", i)
print(f"0 - After optimizer zero_grad: {to_MiB(torch.cuda.memory_allocated(device))}")
with torch.cuda.amp.autocast(enabled=use_amp):
a = torch.cuda.memory_allocated(device)
out = model(sample_input.to(device)).sum() # Taking the sum here just to get a scalar output
b = torch.cuda.memory_allocated(device)
print(f"1 - After forward pass: {to_MiB(torch.cuda.memory_allocated(device))}")
print(f"2 - Memory consumed by forward pass {to_MiB(b-a)}")
out.backward()
print(f"3 - After backward pass: {to_MiB(torch.cuda.memory_allocated(device))}")
optimizer.step()
print(f"4 - After optimizer step: {to_MiB(torch.cuda.memory_allocated(device))}")
print(f"5 - Running max memory: {to_MiB(torch.cuda.max_memory_allocated(device))}")
del out
del sample_input
sample_input = torch.randn(*in_size, dtype=torch.float32)
if __name__ == '__main__':
model = DualModel(1024, 512, double_conv=False, full_input=False)
test_memory_training(model, in_size=(4,1,1024,1024), use_amp=False, device=0)
Is there something I’m missing here? Anyway to make this work?
Thanks