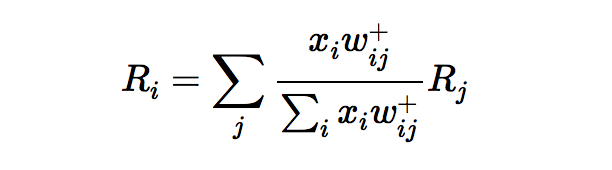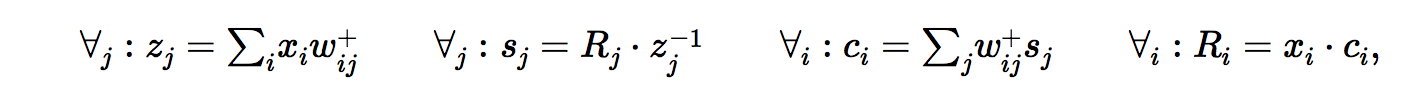Hey guys!
I’ve posted a similar topic and have read all topics that I found about that topic, but I just can’t seem to get it.
I’m trying to implement relevance propagation for convolutional layers.
For this, I need to calculate the gradient of a given layer with respect to its input. Since I have to calculate this gradient for intermediate layers, I do not have a scalar value at my output, but a multidimensional tensor. What I want to achieve is
def relprop(self, R):
pself = copy.copy(self)
pself.bias.data *= 0
pself.weight.data = torch.max(torch.DoubleTensor(1).zero_(), pself.weight)
Z = pself.forward(self.X) + 1e-9
S = torch.div(R, Z)
C = S.backward()
print(self.X.grad)
R = self.X * C
return R
The backwards function should basically compute S * pself.weight, since I try to get the gradient with respect to X, but do this effectively.
My problem now is that I can not calculate the gradient of S, since this is only supported for scalar values. I know I can specify a gradient vector to put into backward(), but I can for the life of me not figure out what to plug in.
This is how I would understand the docs, since the previous gradients should be multiplied to the ones calculated from your operations.
This is weird, since the gradients should be calculated only for the inputs of the operations in the dynamically created graph. Are you sure this is not because of some previous tries which might be still cached or something like that?
Sorry, I have copied the wrong code, apparently. I have, of course, run the forward pass with the newly copied variable x.
I’m still wondering why the gradient was not saved into the self.X variable?
Thanks for your help, by the way!
If you would have only done x = self.X the tensors would still share the same storage and therefore gradients calculated for x would also apply to self.X as they would also share storage. Since you do x = copy.copy(self.X), new storage for x (and it’s gradients) will be allocated. This decouples the tensors from each other and they only have the same underlying data at the beginning (but not the same storage any more!)
Now, I’m kinda confused too. Can you please run each of the following snippets and post their results?
First:
pself = copy.copy(self)
x = copy.copy(self.X)
pself.bias.data *= 0
pself.weight.data = torch.max(torch.DoubleTensor(1).zero_(), pself.weight)
Z = pself.forward(x) + 1e-9
S = torch.div(R, Z)
C = S.backward(torch.ones_like(S))
print(x.grad)
Second:
self.bias.data *= 0
self.weight.data = torch.max(torch.DoubleTensor(1).zero_(), self.weight)
Z = self.forward(self.X) + 1e-9
S = torch.div(R, Z)
C = S.backward(torch.ones_like(S))
print(self.X.grad)
Third:
pself = copy.copy(self)
x = copy.copy(self.X)
pself.bias.data *= 0
pself.weight.data = torch.max(torch.DoubleTensor(1).zero_(), pself.weight)
Z = pself.forward(x) + 1e-9
S = torch.div(R, Z)
C = torch.autograd.grad(S, x, torch.ones_like(S))
And fourth:
self.bias.data *= 0
self.weight.data = torch.max(torch.DoubleTensor(1).zero_(), self.weight)
Z = self.forward(self.X) + 1e-9
S = torch.div(R, Z)
C = torch.autograd.grad(S, self.X, torch.ones_like(S))
Also note, that you should not do something like module.forward(x) but module(x) instead (if module is an instance of torch.nn.Module) since this will internally call the forward function but do some other stuff which is needed for hooks etc to make them work properly.
Can you try it with just some other random tensors instead of self.X to ensure that it is not a unfortunate operation on self.X which is causing that behavior?
x = torch.randn((self.X.shape), requires_grad=True)
does indeed work. It must be something with self.X sharing the same memory, with pself, so when I use pself.forward, it overwrites the old self.X, so that the new one does not have a gradient…