I tried to predict option pricing using GRU-RNN . Its giving me straight line as predicted values for timeseries data.
here is code of my neural net.
class GRUnets(nn.Module):
def __init__(self, num_features, num_rows, batch_size, hidden_size, num_layers):
"""Initialize the model by setting up the layers"""
super(GRUnets, self).__init__()
self.num_features = num_features
self.num_rows = num_rows
self.batch_size = batch_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.rnn = nn.GRU(batch_first=True, input_size=self.num_features,hidden_size=self.hidden_size, num_layers = self.num_layers)
# init GRU hidden layer
# self.hidden = self.init_hidden(batch_size=self.batch_size, hidden_size=hidden_size)
# dropout layer
self.dropout = nn.Dropout(0.3)
# 2 fully-connected hidden layers - with an output of dim 1
self.link_layer = nn.Linear(self.hidden_size, 1000)
self.dense1 = nn.Linear(1000, 500)
self.dense2 = nn.Linear(500, 512)
# output layer
self.dense4 = nn.Linear(512, 1)
self.sigmoid = nn.Sigmoid()
self.leakyReLU = nn.LeakyReLU(0.2)
def forward(self, x):
"""Perform a forward pass of our model on some input and hidden state"""
# GRU layer
x, self.hidden = self.rnn(x)
# print(x.shape,self.hidden.shape)
x = x.squeeze()
# detatch the hidden layer to prevent further backpropagating. i.e. fix the vanishing gradient problem
# self.hidden = self.hidden.detach().to(device)
# apply a Dropout layer
# x = self.dropout(x)
# pass through the link_layer
x = self.link_layer(x)
x = self.leakyReLU(x)
# apply 2 fully-connected Linear layers with activation function
x = self.dense1(x)
x = self.leakyReLU(x)
x = self.dense2(x)
x = self.leakyReLU(x)
# output is a size 1 Tensor
x = self.dense4(x)
return x
def init_hidden(self, batch_size, hidden_size):
"""Initializes hidden state"""
# Creates initial hidden state for GRU of zeroes
hidden = torch.zeros(self.num_layers, self.num_rows, hidden_size).to(device)
return hidden
model = GRUnets(5,1,1,512,2) # Instantiating the model
loss_fn = nn.MSELoss() # Choosing the Loss Function as Mean Squared Error since the task is regression
model = model.to(device) # Moving the model to device ('cuda' or 'cpu')
model = model.float()
optimizer = optim.Adam(model.parameters(),lr=1e-2) # Choosing Adam optimizer with learning_rate-1e-4. Assigning model's
and this is what is get as result.
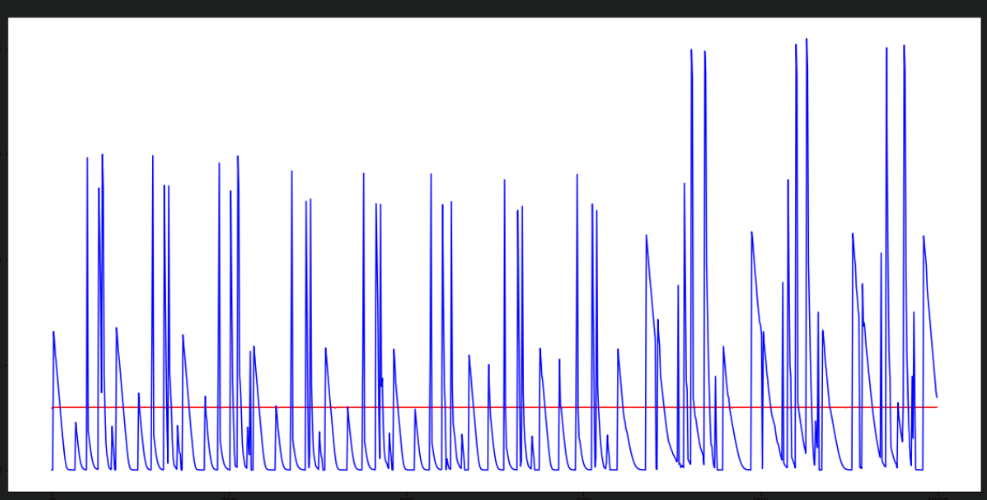
I can’t understand why is that happeneing so as newbie to pytorch I would be happy if someone here help me solve this issue
Thanks.