A GRU is defined in Torch as
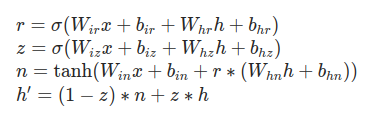
As I understand, the trainable weights are W_ir, W_hr, W_iz, W_hz, W_in and W_hn along with their biases. However, if I define a GRU and print its state_dict():
rnn = nn.GRU(1, 1, 1)
print(rnn.state_dict())
I get
OrderedDict([('weight_ih_l0', tensor([[0.8447],
[0.0636],
[0.3000]])), ('weight_hh_l0', tensor([[-0.2396],
[ 0.2593],
[-0.7984]])), ('bias_ih_l0', tensor([-0.8617, -0.9971, -0.0588])), ('bias_hh_l0', tensor([0.9238, 0.1282, 0.9144]))])
According to the documentation,
~GRU.weight_ih_l[k] – the learnable input-hidden weights of the kth\text{k}^{th}kth layer (W_ir|W_iz|W_in), of shape (3*hidden_size, input_size) for k = 0. Otherwise, the shape is (3*hidden_size, num_directions * hidden_size)
weight_ih_l0 seems to encompass W_ir, W_iz, W_in, but there’s only one set of weights for it. Same goes with weight_hh_l0. Does this mean these weights are being shared?