Good afternoon everyone,
I am new to PyTorch and I am having trouble with my code. The problem is that it seems that the operation that I am using is inplace, but I cant seem to understand how to fix it.
class GCNNet(torch.nn.Module):
def __init__(self, embedding_dim=10, hidden_dim=10, dropout=0, with_edge_attention=True, \
with_node_attention=True):
super(GCNNet, self).__init__()
self.dropout = dropout
self.conv1 = GCNConv(embedding_dim, hidden_dim, cached=True, normalize=True)
self.conv2 = GCNConv(hidden_dim, hidden_dim, cached=True, normalize=True)
self.with_node_attention = with_node_attention
self.with_edge_attention = with_edge_attention
self.node_att_mlp = nn.Linear(embedding_dim, 2)
self.edge_att_mlp = nn.Linear(embedding_dim * 2, 2)
def forward(self, x, edge_index): #x.shape ([132, 50])
row, col = edge_index
edge_rep = torch.cat([x[row], x[col]], dim=-1) #([1208, 100])
if self.with_node_attention:
node_att = self.node_att_mlp(x)
node_att = F.softmax(node_att, dim=-1) #([1208, 2])
else:
node_att = 0.5 * torch.ones(x.shape[0], 2).cuda()
if self.with_edge_attention:
edge_att_mlp = self.edge_att_mlp(edge_rep) # [1208,100] == > [1208,2]
edge_att = F.softmax(edge_att_mlp, dim=-1) #[1208, 2]
else:
edge_att = 0.5 * torch.ones(edge_rep.shape[0], 2).cuda()
node_weight_c = node_att[:, 0] #node_weight_t = node_att[:, 1]
edge_weight_c = edge_att[:, 0] #edge_weight_t = edge_att[:, 1]
xc = node_weight_c.view(-1, 1) * x #[132, 50])
#xt = node_weight_t.view(-1, 1) * x
xc = xc + self.conv1(xc, edge_index, edge_weight_c)
xc = F.relu(xc)
xc = F.dropout(xc, self.dropout, training=self.training)
xc = xc + self.conv2(xc, edge_index, edge_weight_c)
return xc
The error message is as follow:
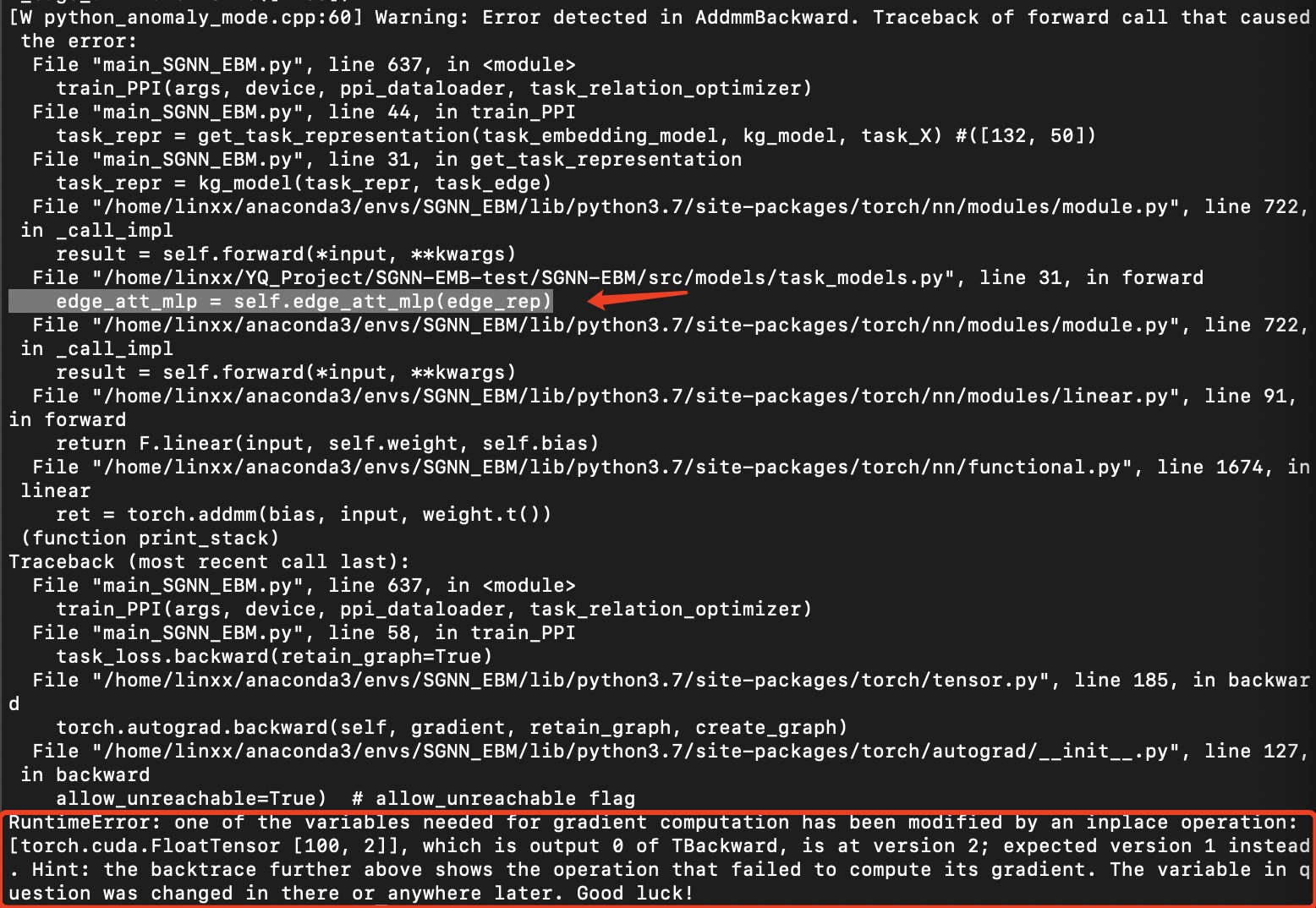
Thanks a lot for helping me out!
Vicky