Hello everyone. I am facing an issue. I am explaining what I am trying to do.
I have a Traffic and Road sign dataset that contains 43 classes. I am trying to classify the images. I am using the resnet34 pre-trained model. I have AMD RX6600 GPU that I use for running the model. For running the model on my AMD GPU I am using Pytorch Directml and using this code
import torch_directml
dml = torch_directml.device()
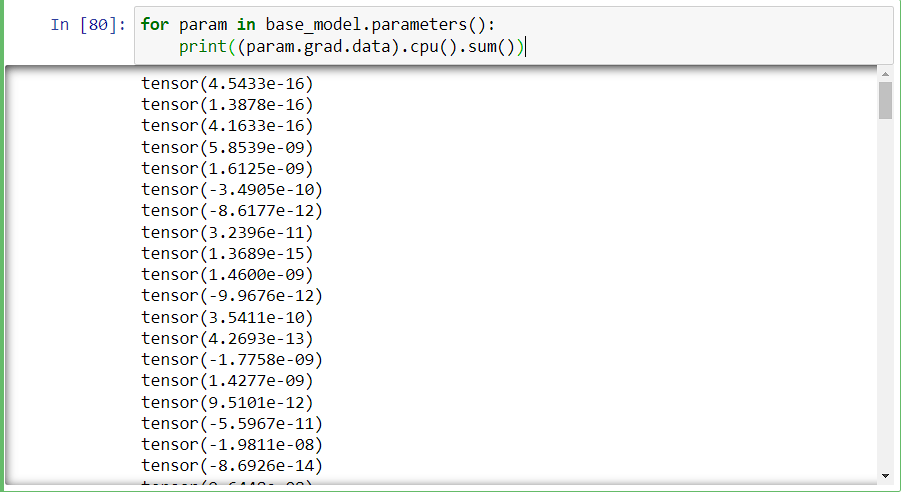
to find the device. The using this dml instance, I push the mode and training data to the GPU. Until now everything has worked fine. Training speed is fast enough, and GPU utilization is near 100%. Training loss decreases per epoch. But when I check the model using validation data after one training phase, validation loss increases and validation accuracy is too low. But training is ok. When I run the same code on my friend’s PC who has NVIDIA GPU, all is ok. Validation loss decreases and it converges. And I got an accuracy of 98% when running the same code on NVIDIA GPU. I can not figure out what the problem is. I also tune the hyperparameter but had no luck. And one strange thing is that this problem arises when I use CNN based model. I had run NLP pre-trained model BERT on my AMD GPU and there is no Issue. Validation loss decreases and it converges. Can anyone help me with this issue? I am giving the code below. Thanks in advance.
Model Initialization
def create_model():
model = torchvision.models.resnet34(weights='ResNet34_Weights.DEFAULT')
n_features = model.fc.in_features
model.fc = nn.Sequential(
nn.Linear(n_features, 256),
nn.ReLU(),
nn.Linear(256, 128),
nn.ReLU(),
nn.Linear(128, 43)
)
return model.to(dml)
base_model = create_model()
Hyper parameters
num_classes = 43
num_epochs = 10
learning_rate = 1e-4
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(base_model.parameters(), lr=learning_rate)
Training and Validation loop
def train_model():
since = time.time()
val_acc_history = []
best_model_wts = copy.deepcopy(base_model.state_dict())
best_acc = 0.0
progress_bar_train = tqdm(range(num_epochs * len(train_loader)))
progress_bar_eval = tqdm(range(num_epochs * len(validation_loader)))
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'val']:
if phase == 'train':
base_model.train() # Set model to training mode
else:
base_model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(dml)
labels = labels.to(dml)
# zero the parameter gradients
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'train'):
outputs = base_model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
progress_bar_train.update(1)
elif phase == 'val':
progress_bar_eval.update(1)
running_loss += loss.item() * inputs.size(0)
preds = preds.cpu()
labels = labels.data.cpu()
running_corrects += (preds == labels).sum()
print("Lenght: ", len(dataloaders[phase].dataset))
epoch_loss = running_loss / len(dataloaders[phase].dataset)
epoch_acc = float(running_corrects) / len(dataloaders[phase].dataset)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
# deep copy the model
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(base_model.state_dict())
if phase == 'val':
val_acc_history.append(epoch_acc)
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# load best model weights
base_model.load_state_dict(best_model_wts)
return base_model, val_acc_history
Calling the training function
best_model, validation_acc_hist = train_model()
Please help me