I was looking at the hogwild example. Here the model is evaluated on the test data within each process. Shouldn’t the right way be to first train the model in different processes, wait for the processes to terminate and then do an evaluation over test data? Or the asynchronous updates (to the model from different processes) makes it unnecessary.
@shagunsodhani yes, you are correct. But to keep the code simple (as its an example), we are doing some identical work.
I’d be willing to accept a PR that keeps it simple, but does what you are saying we should do.
@smth I am sorry. I never realized that you had replied to it. I have now enabled notifications.
For the PR, I have raised one here.
I have been trying some experiments with hogwild and have some questions. Let me describe my setup first.
I first divide my training data into k disjoint sets. Then I setup k processes which are sharing the model but each has a separate train dataset. Note that the test dataset is shared between all the processes. Each process is run for n epochs, Each process performs the standard train-test iterations (training using only its split, testing using the entire dataset). Once all the processes are completed, I do one more round of testing, in the main process.
I observe once n epcohs have been performed, all processes report the same test performance, which is the same as the test performance reported by the main process (once every other process has terminated).
I could not figure out when the updates are shared between the different processes. Is it done per-epoch or after a fixed time interval or fixed number of training steps? This affects which strategy (of deciding when to test) is optimal.
There are several strategies for training/testing the model:
(i) Train the k processes for n epoch and test only once after all the processes have terminated. The upside is - testing is done just 1 time and not k*n times. It is also the simplest strategy. The downside is, we can not do early stopping and need to know n in advance.
(ii) Train the k processes for 1 epoch, wait for all the process to terminate, do testing, then again train the k process for 1 epoch. the upside is now we can perform early stopping while we test just n times. The downside is, there is an additional wait period where k-1 processes are sitting idle. I suppose the additional overhead of triggering k processes per epoch would be negligible.
(iii) Train k process for n epochs. Each process implements early-stopping for itself, This is essentially what is happening in the example right now. One downside is the extra testing but in terms of time-taken I think this would be very similar to the second strategy.
(iv) Out of the k processes, only 1 process does the testing. All other processes just train on the data. the process which also tests would lag behind but atleast all other processes could move faster. This also allows for early stopping and is not too complex. Alternatively, we could have reserved a process just for testing but that slows down the training and performs “extra” testing.
Among all these options, I think (iv) is the best one provided its guaranteed that the updates are synchronized between the processes at regular intervals. But I am not sure when and how the updates are applied between the processes. What are your thoughts?
I could not figure out when the updates are shared between the different processes.
The updates aren’t shared between processes at all. All processes are seeing the same memory for the weights, so regardless of who updates the weights, all of them see updated weights.
On (1), yes you need validation once in a while, so not ideal. (2) should actually be fine to do, practically – train time is much greater than process sync time. (4) is fine, but all the other processes have to stop training while one of the process is doing the testing, or else you have the situation where – “while testing in process 0, process 1 updates weights, hence testing network for validation sample 0 is not the same as testing network for validation sample 1”
2 Likes
@smth Helps a lot. Thank you. Just to visualize it, does the pic below represent what you are saying in the text about model.share_memory()
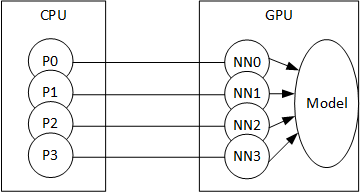
Hi, we also want to know how multiprocessing via model.share_memory() can affect our training performance or we won’t need to worry about this. @smth
I am using multiprocessing framework to speed up the CPU processing data into tensor following the best practice on
https://pytorch.org/docs/stable/notes/multiprocessing.html
suppose I have list [1,2,...32] dataset, I have 2 outer process, each process with a 4 worker data loader, so
- process 1 will load
[1,2,3,4]
...
[13,14,15,16]
- process 2 will load
[17,18,19,20]
...
[29,30,31,32]
so in each process, I have 4 worker data loader, so let’s see one data loader in process1 will only load
[1,2,3,4] .
all these process and multi worker dataloader is to speed up the data loading and data cooking, however, I only have one GPU and one model, so in this case, if I use model().share_memory() ? so each process will just process partial dataset, but their tensor will be shared inside GPU, so final model will have all trained gradient and I don’t need to worry like race condition or so?