As you can see I need to use this kind of data during my training process, so IO has been a huge problem.
I also use DDP, which makes me tougher to adjust my code.
Is there a way in pytorch can handle this problem? Help me, please.
As you can see I need to use this kind of data during my training process, so IO has been a huge problem.
I also use DDP, which makes me tougher to adjust my code.
Is there a way in pytorch can handle this problem? Help me, please.
What kind of IO problem are you seeing?
Loading data for training might take 10 seconds+,which makes my GPU -util 0% at the most of time.
You could try to increase the number of workers so that the loading latency might be hidden in the background while the model is training. Also, if you are using an older HDD, try to move the data to a faster SSD to speed up the loading time.
I have already tried to increase the number of workers, and I found 4 is the best for my code.
The size of training data is about 400G, I don’t have SSD as that big.
But my HHD should be fast enough, almost 6GB/s.
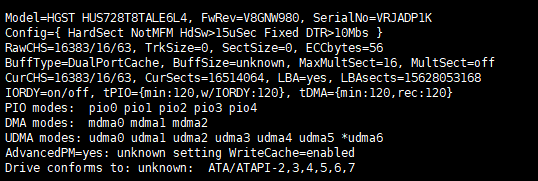
I don’t think your HDD can achieve this bandwidth and based on e.g. these newegg specs you could get ~255MB/s:
this 3.5-inch drive features 8TB capacity, 7200RPM spinning speed, SATA 6 Gbps host interface and 256 MB Cache, and delivers sustained transfer rate of up to Up to 255 MB/s (for reference only)
You could also profile the read speed to check the “for reference only” claim and might see a lower performance.
I think the main problem might not be the speed of my HDD but the way I load files.
Every training I have to load 64 files of the size of 1.7M.
The operation to load files of this size might cause cpu jam.
Is there any way I can build a big file to save the data stocking in this file?
Loading a big file should be faster than a bunch of files of not small size.
Yes, you could load multiple numpy files in a script, concatenate the arrays (assuming their shape allows it), and save the newly created (bigger) numpy array again.
Maybe LMDB is a feasible way to solve my problem, what do you think?