Thank you so much for your reply!
Your sample code gave me inspiration for the following toy model
import torch
torch.manual_seed(2810)
# input
x = torch.randn(5, requires_grad=True)
# model
class simple(torch.nn.Module):
def __init__(self):
super(simple, self).__init__()
self.layer = torch.nn.Linear(5, 1, bias=False)
def forward(self, in_):
return self.layer(in_)
model = simple()
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
model.zero_grad()
y = torch.log(model(x))
loss = y
print('input x: ', x)
> input x: tensor([-0.6195, 1.2090, 0.7255, 0.3041, -1.8422], requires_grad=True)
print('layer weights: ', model.layer.weight.data)
> layer weights: tensor([[ 0.0566, 0.3471, 0.0256, -0.3857, 0.2482]])
print('loss: ', loss)
> loss: tensor([nan], grad_fn=<LogBackward>)
then I calculated gradients and backpropagated
loss.backward()
print('layer weights: ', model.layer.weight.data)
> layer weights: tensor([[ 0.0566, 0.3471, 0.0256, -0.3857, 0.2482]])
print('layer weights grad: ', model.layer.weight.grad)
> layer weights grad: tensor([[ 3.6150, -7.0544, -4.2334, -1.7744, 10.7490]])
optimizer.step()
print('layer weights: ', model.layer.weight.data)
> layer weights: tensor([[ 0.0530, 0.3542, 0.0298, -0.3840, 0.2374]])
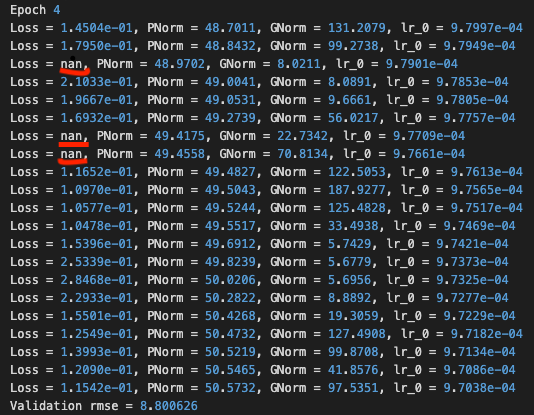
The model could obtain gradients of the layer weights and update the weights even if the loss is ‘nan’!
I think the optimizer has another strategy to update the model’s weights when receiving a ‘nan’ loss,
but I’m still looking for the answer…
Thank you so much again for your kind reply, you really saved my time!