import os
import torch
import torch.distributed as dist
from torch.multiprocessing import Process
def run(rank, size):
tensor1 = torch.ones(1, device=2*rank)
tensor2 = torch.ones(1, device=2*rank+1)
dist.all_reduce(tensor1, op=dist.ReduceOp.SUM)
dist.all_reduce(tensor2, op=dist.ReduceOp.SUM)
print('Rank ', rank, ' has data ', tensor1[0], tensor2[0])
def init_process(rank, size, fn, backend='nccl'):
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29501'
dist.init_process_group(backend, rank=rank, world_size=size)
fn(rank, size)
if __name__ == "__main__":
size = 2
processes = []
for rank in range(size):
p = Process(target=init_process, args=(rank, size, run))
p.start()
processes.append(p)
for p in processes:
p.join()
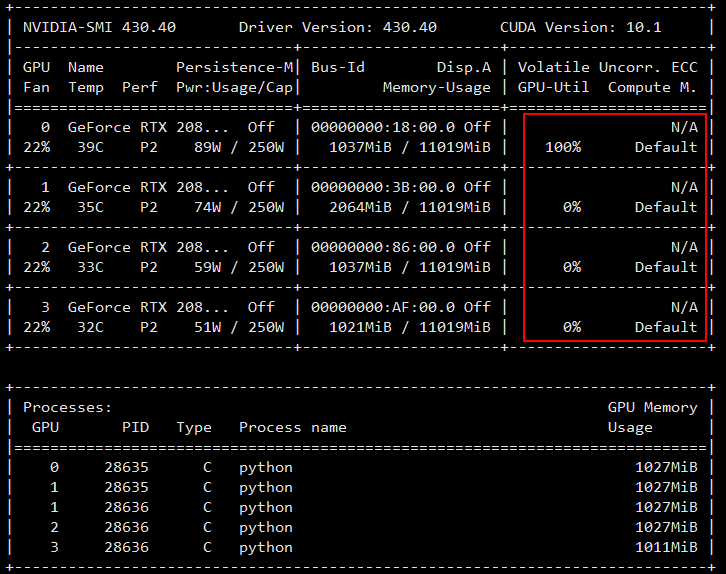
I have a computer with four GPUs,
GPU0: tensor1, GPU1: tensor2
GPU2: tensor1, GPU3: tensor2
I expect to reduce tensor1 in GPU0 and GPU2, reduce tensor2 in GPU1 and GPU3. But when I execute the above code, the program keeps blocking.
I don’t know why. Can someone help me, thanks!