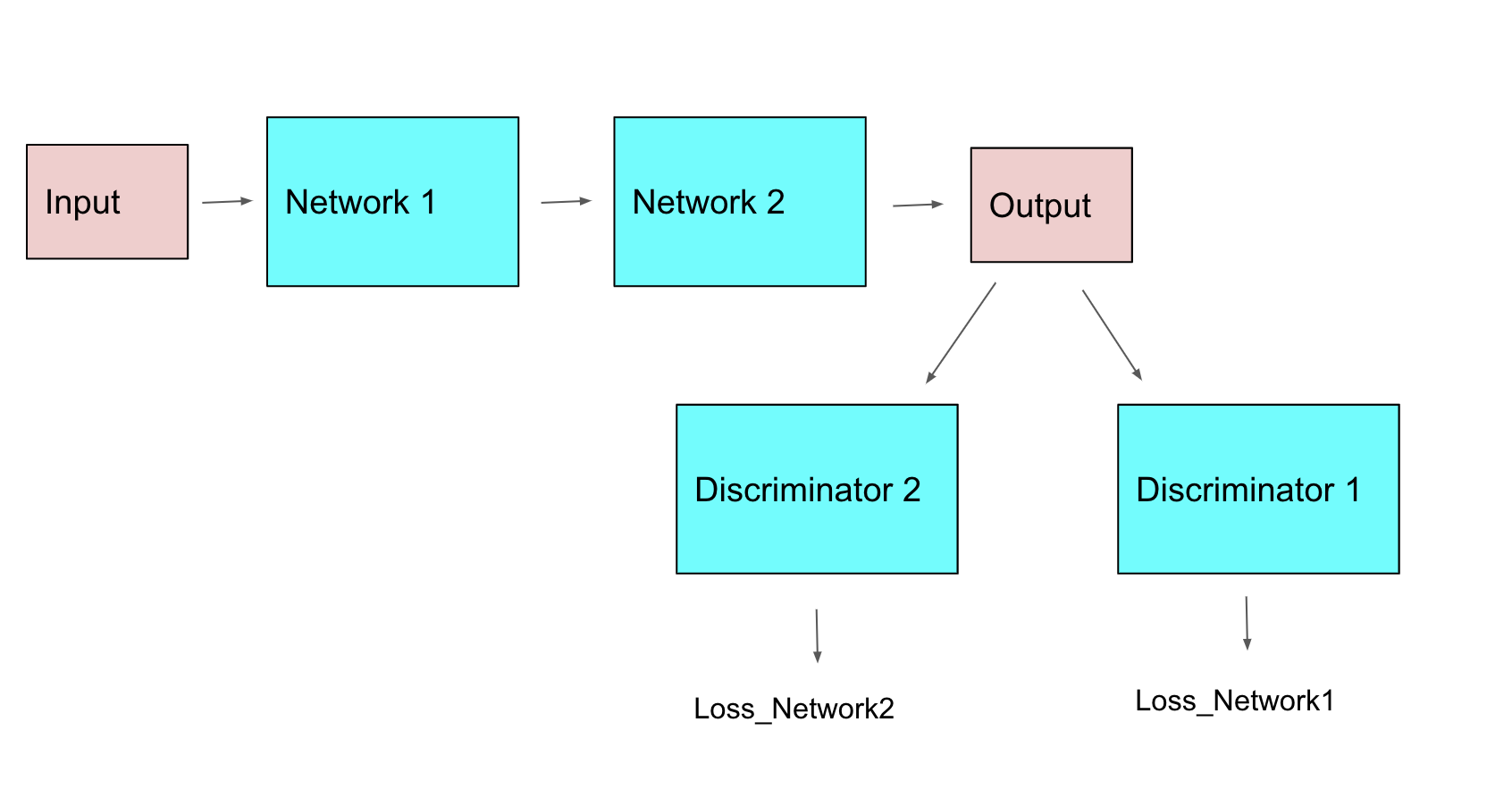
The image is a simplified version of my network. I want to update Network1 with Loss_Network1 and Network2 with Loss_Network2. However, when I do backward(), the grads will be calculated for them regardless (ex: the grads for Loss_Network1 is added onto the .grad of Network2). The only approach I can think of now is:
Loss_Network1.backward()
optimizer_Network2.zero_grad()
copy the .grad for Network1
Loss_Network2.backward()
optimizer_Network1.zero_grad()
copy back the .grad for Network1
optimizer_Network1.step()
optimizer_Network2.step()
and also, doing optimizer_Network1.step() before Loss_Network2.backward() although may seem obvious but isn’t an option because that way it will raise: RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation
Please let me know if there’s is a simple way to maybe freeze .grad in backward() so that I won’t need to copy the .grad s. Thanks!!
I’m afraid this is not easy to do. And what you’re doing right now is pretty close to optimal.
The only other approach would be to do two forwards, one for lossnet1 and one for lossnet2 and only update the corresponding net before doing the other’s backward. But this will be slower I’m afraid.
Thanks for the reply! I just thought of another possible solution. Can we do something like stopping the back propagation at some point? like stop it in between Net1 and Net2?