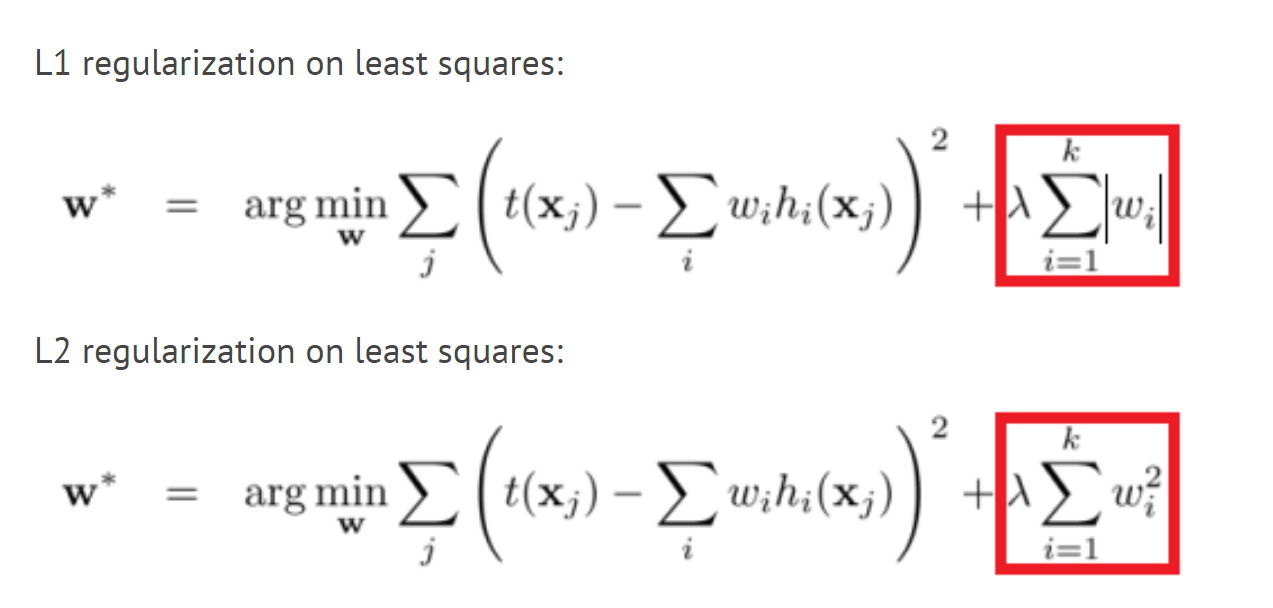I can’t see why multiplying by 0.5 would improve anything…? Except of course if you are using the 0.5 as the lambda, but that value is entirely arbitrary then.
It’s practically insubstantial. Originally people used the 1/2 factor because it makes the notation simpler when calculating the derivatives on paper. If you omit it, your optimal lambda values will simply be half as large as what other people (who have used the common 1/2 formulation) report in their papers.
If you want a quick explanation why this should be done look at the formulas that @Esteban_Lanter posted: the first term is simply the sum whereas in @Brando_Miranda 's implementation this term is divided by N_train. If you want to use the later, you also have to divide the regularization by the same scaling, otherwise you will destroy the balance between the two terms.
If you want a more detailled explanation why this should be done (and why the factor 0.5 makes sense), have a look into the Bayesian interpretation of L2 (or L1) regularization
Why OP has user .norm on the weights? As per the L1 & L2 formulas, it should be either abs (in L1) or pow(2) (in L2) for the model’s weights. Isn’t it?
What I’m missing here ? Can anybody please explain it to me?