It appears that this is fixed by Don't split oversize cached blocks by mwootton · Pull Request #44742 · pytorch/pytorch · GitHub. May I know the version of the PyTorch this is fixed in?
@ptrblck
It should be available in PyTorch >=1.10.0.
1 Like
Still the same issue. after trying different version
CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 4.00 GiB total capacity; 2.60 GiB already allocated; 0 bytes free; 2.64 GiB reserved in total by PyTorch)
The other 2 GB of GPU are not being used, just reserved for nothing.
Your current workload hat 2.6GB allocated and approx. 40MB in the cache which might be fragmented and thus won’t be able to be used for the desired 20MB tensor. The rest is used by the CUDA context as well as other applications.
Then any suggestion on how to solve this, like how can I devote all of it just for pytorch.
Check if other applications are using the GPU e.g. via nvidia-smi and close them if possible.
RuntimeError: CUDA out of memory. Tried to allocate 18.00 MiB (GPU 0; 4.00 GiB total capacity; 3.49 GiB already allocated; 0 bytes free; 3.53 GiB reserved in total by PyTorch)
I have what appears to be a fairly extreme case of this:
CUDA out of memory. Tried to allocate 26.00 MiB (GPU 0; 15.74 GiB total capacity; 1.44 GiB already allocated; 25.56 MiB free; 1.47 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
I have ~16GB capacity, but for some reason only 1.47 GB is reserved by PyTorch. Furthermore, I am running it on a fresh Paperspace cluster that is doing literally nothing other than downloading a Huggingface model for inference. It would be great to understand what might be happening here!
Still no solution to this issue??
![]()
![]()
I am running into the same problem since yesterday. I am using Torch Version 1.13.0+cu117 and Cuda Version 11.0. My batch_size is 3, the image has a size of 1000*2000, U-Net architecture for image segmentation.
I am already deleting the cuda cache before transfering X and y to cuda using torch.cuda.empty_cache(). Additionally I am deleting X, y and y_hat after every optimizer.step() using “del X, y, y_hat”. This helped to increase batchsize from 1 to 5.
Still the error message shows up: “torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 184.00 MiB (GPU 0; 14.76 GiB total capacity; 13.60 GiB already allocated; 113.75 MiB free; 13.65 GiB reserved in total by PyTorch)”
torch.cuda.memory_stats(device ). I am a bit lost since its my first time working with CUDA and I am not seeing any promising solutions online. I would be happy about any help here ![]()
Using “nvidia-smi” command proves, that there are no other processes running on the gpu.
I am printing some CUDA stats before and after transfering X and y to the GPU:
Tesla T4 (torch.cuda.get_device_name)
Device Count: 1 device(s) (torch.cuda.device_count)
Currently used device: 0 device(s) (torch.cuda.current_device)
Memory Allocated (Device): 0.2 GB (torch.cuda.memory_allocated)
Max Memory Allocated: 0.2 GB (torch.cuda.max_memory_allocated)
Memory Reserved: 0.2 GB (torch.cuda.memory_reserved)
X and y transfered to cuda
Start prediction
Tesla T4
Device Count: 1 device(s)
Currently used device: 0 device(s)
Memory Allocated (Device): 0.3 GB
Max Memory Allocated: 0.3 GB
Memory Reserved: 0.3 GB
Additionally I am saving the CUDA memory stats right before the “y_hat = model(X)” step runs into the error.
{
“active.all.allocated”: 356,
“active.all.current”: 238,
“active.all.freed”: 118,
“active.all.peak”: 238,
“active.large_pool.allocated”: 28,
“active.large_pool.current”: 28,
“active.large_pool.freed”: 0,
“active.large_pool.peak”: 28,
“active.small_pool.allocated”: 328,
“active.small_pool.current”: 210,
“active.small_pool.freed”: 118,
“active.small_pool.peak”: 211,
“active_bytes.all.allocated”: 347500544,
“active_bytes.all.current”: 347440128,
“active_bytes.all.freed”: 60416,
“active_bytes.all.peak”: 347440128,
“active_bytes.large_pool.allocated”: 341760000,
“active_bytes.large_pool.current”: 341760000,
“active_bytes.large_pool.freed”: 0,
“active_bytes.large_pool.peak”: 341760000,
“active_bytes.small_pool.allocated”: 5740544,
“active_bytes.small_pool.current”: 5680128,
“active_bytes.small_pool.freed”: 60416,
“active_bytes.small_pool.peak”: 5680640,
“allocated_bytes.all.allocated”: 347500544,
“allocated_bytes.all.current”: 347440128,
“allocated_bytes.all.freed”: 60416,
“allocated_bytes.all.peak”: 347440128,
“allocated_bytes.large_pool.allocated”: 341760000,
“allocated_bytes.large_pool.current”: 341760000,
“allocated_bytes.large_pool.freed”: 0,
“allocated_bytes.large_pool.peak”: 341760000,
“allocated_bytes.small_pool.allocated”: 5740544,
“allocated_bytes.small_pool.current”: 5680128,
“allocated_bytes.small_pool.freed”: 60416,
“allocated_bytes.small_pool.peak”: 5680640,
“allocation.all.allocated”: 356,
“allocation.all.current”: 238,
“allocation.all.freed”: 118,
“allocation.all.peak”: 238,
“allocation.large_pool.allocated”: 28,
“allocation.large_pool.current”: 28,
“allocation.large_pool.freed”: 0,
“allocation.large_pool.peak”: 28,
“allocation.small_pool.allocated”: 328,
“allocation.small_pool.current”: 210,
“allocation.small_pool.freed”: 118,
“allocation.small_pool.peak”: 211,
“inactive_split.all.allocated”: 10,
“inactive_split.all.current”: 7,
“inactive_split.all.freed”: 3,
“inactive_split.all.peak”: 7,
“inactive_split.large_pool.allocated”: 7,
“inactive_split.large_pool.current”: 4,
“inactive_split.large_pool.freed”: 3,
“inactive_split.large_pool.peak”: 4,
“inactive_split.small_pool.allocated”: 3,
“inactive_split.small_pool.current”: 3,
“inactive_split.small_pool.freed”: 0,
“inactive_split.small_pool.peak”: 3,
“inactive_split_bytes.all.allocated”: 76647424,
“inactive_split_bytes.all.current”: 13270016,
“inactive_split_bytes.all.freed”: 63377408,
“inactive_split_bytes.all.peak”: 20480000,
“inactive_split_bytes.large_pool.allocated”: 70723584,
“inactive_split_bytes.large_pool.current”: 12658688,
“inactive_split_bytes.large_pool.freed”: 58064896,
“inactive_split_bytes.large_pool.peak”: 19529728,
“inactive_split_bytes.small_pool.allocated”: 5923840,
“inactive_split_bytes.small_pool.current”: 611328,
“inactive_split_bytes.small_pool.freed”: 5312512,
“inactive_split_bytes.small_pool.peak”: 2170880,
“max_split_size”: -1,
“num_alloc_retries”: 0,
“num_ooms”: 0,
“oversize_allocations.allocated”: 0,
“oversize_allocations.current”: 0,
“oversize_allocations.freed”: 0,
“oversize_allocations.peak”: 0,
“oversize_segments.allocated”: 0,
“oversize_segments.current”: 0,
“oversize_segments.freed”: 0,
“oversize_segments.peak”: 0,
“reserved_bytes.all.allocated”: 360710144,
“reserved_bytes.all.current”: 360710144,
“reserved_bytes.all.freed”: 0,
“reserved_bytes.all.peak”: 360710144,
“reserved_bytes.large_pool.allocated”: 354418688,
“reserved_bytes.large_pool.current”: 354418688,
“reserved_bytes.large_pool.freed”: 0,
“reserved_bytes.large_pool.peak”: 354418688,
“reserved_bytes.small_pool.allocated”: 6291456,
“reserved_bytes.small_pool.current”: 6291456,
“reserved_bytes.small_pool.freed”: 0,
“reserved_bytes.small_pool.peak”: 6291456,
“segment.all.allocated”: 16,
“segment.all.current”: 16,
“segment.all.freed”: 0,
“segment.all.peak”: 16,
“segment.large_pool.allocated”: 13,
“segment.large_pool.current”: 13,
“segment.large_pool.freed”: 0,
“segment.large_pool.peak”: 13,
“segment.small_pool.allocated”: 3,
“segment.small_pool.current”: 3,
“segment.small_pool.freed”: 0,
“segment.small_pool.peak”: 3
}
I didn’t solve the initial problem but I found a workaround, which might help some other people facing the same issue:
I had my model with U-Net architecture implemented from scratch. I recently changed to the segmentation models pytorch library (GitHub - qubvel/segmentation_models.pytorch: Segmentation models with pretrained backbones. PyTorch.), which reduces model integration to just a couple of lines of code. After the change I have no problem with GPU memory anymore, even with way higher batch size.
1 Like
I don’t understand how memory allocation works with CUDA @ptrblck
RuntimeError: CUDA out of memory. Tried to allocate 294.00 MiB (GPU 0; 2.00 GiB total capacity; 185.23 MiB already allocated; 793.77 MiB free; 278.00 MiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
Here it says that I have 793.77 MiB free and PyTorch only reserves 278 MiB. Why? and how can I change the allocation size?
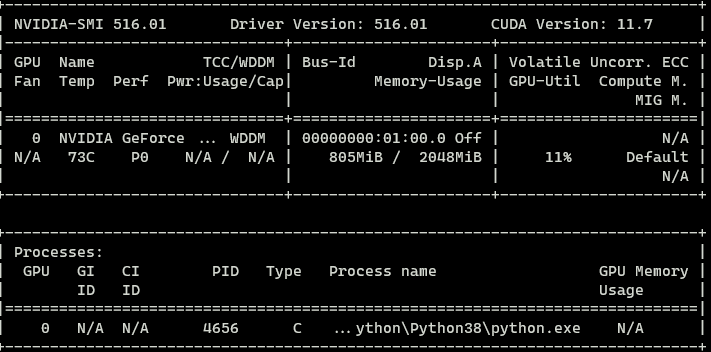
Here’s my nvidia-smi this for some reason shows 805 MiB memory usage. Are there any fixes for this?
Running a Jupyter notebook locally on my RTX2060 Super - no other workloads on the GPU.
The error I was getting was:
OutOfMemoryError: CUDA out of memory. Tried to allocate 734.00 MiB (GPU 0; 7.79 GiB total capacity; 5.20 GiB already allocated; 139.94 MiB free; 6.78 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
I found I could avoid the error by prefixing my code with
import os
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "max_split_size_mb:734"
But of course, this isn’t much of a solution, since I only knew to set to 734 after getting the error. There was a warning that setting this max_split_size_mb might degrade performance, so I did some experiements.
Setting to any amount over 734M (my specific alloc request size - ymmv) drew the OOM error. Setting the value to any amount below that amount, avoided the error. So I tried 733M, 512M, 256M, 64M and 32M - each resulted in avoidance of OOM and a reduction in overall train time.
I’ve been looking through the docs to find insights on how PyTorch CUDA memory alloc works but I don’t quite have a handle on it yet - it seems that PyTorch gets a memory allocation from the GPU that it manages (which is how it can run out of memory when there’s lots on the GPU), but I’m not sure how best to ‘help’ it when it runs into trouble like this.
2 Likes
Anyone found an actual solution to this issue?