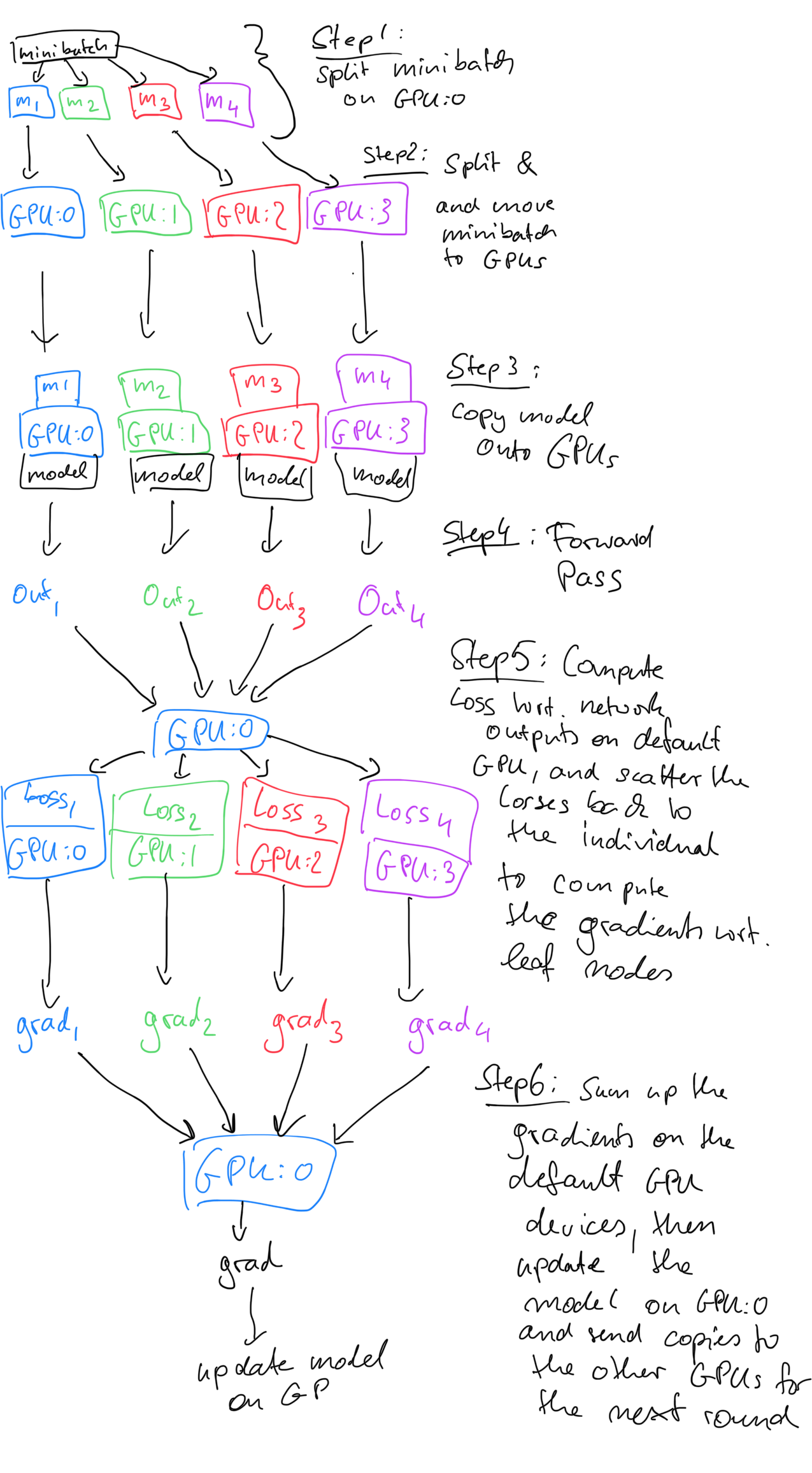
I am not sure about DistributedParallel but in DataParallel each GPU gets a copy of the model, so, the parallelization is done via splitting the minibatches, not the layers/weights.
Here’s a sketch of how DataParallel works, assuming 4 GPUs where GPU:0 is the default GPU.